
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
統計分析
透過嚴謹的數據整理,提供有價值的資訊,形塑知識,提高決策品質。包括信達雅三執行原則。
信:確保資料品質可信賴
達:確保統計方法適切性
雅:確保圖文表格正規化
協助代執行統計分析與進一步加值服務。
在匯東華與夥伴的專業背景知識配合下,能有效地處理面對的問題。
了解更多
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
教材勘誤區
生物統計學系列
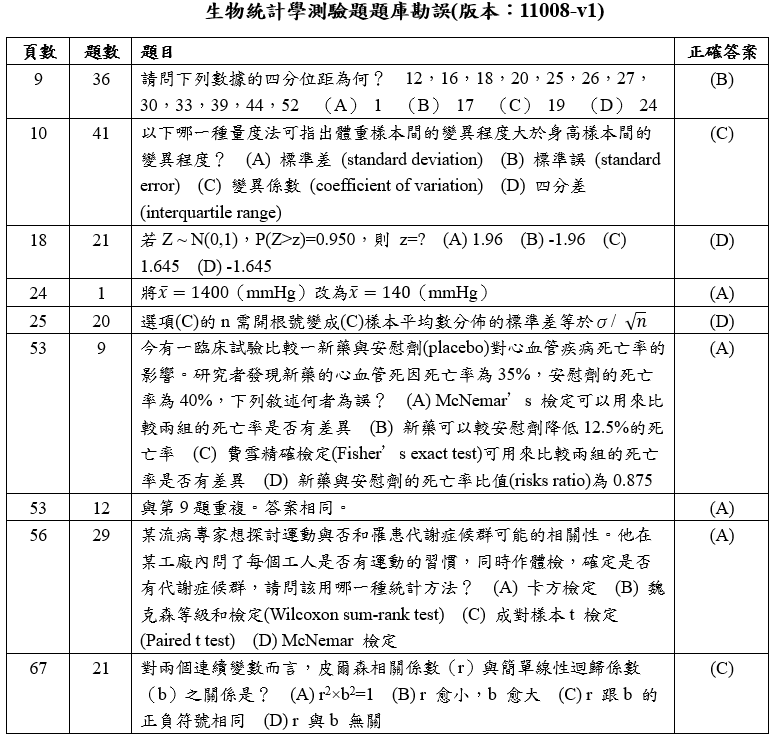
生物統計學測驗題題庫勘誤(版本:11008-v1)
111-112年高等考試公共衛生師生物統計學試題解析(2023.11)勘誤
1.第111年測驗題第26題,修正解析說明
26.想研究高中生男女的體脂肪有無差異,隨機收集了年齡相近的 13 位男生與 11 位女生,描述統計如下所示。欲以 two sample t-test 檢定,若假設兩組變異數相等,此變異數(pooled variance)的估計值最接近之數值為何? (A)35 (B)36 (C)37 (D)38
|
組別 |
樣本數(n) |
平均數 |
標準差(s) |
|
女同學 |
11 |
22 |
5 |
|
男同學 |
13 |
15 |
7 |
解析:

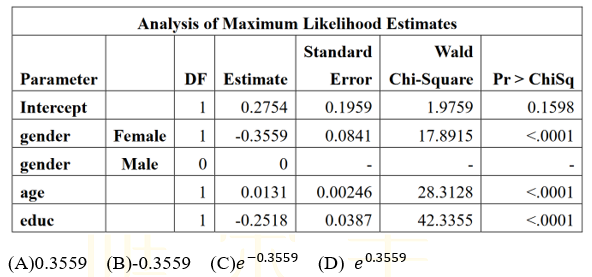
28.分析年齡(age)、性別(gender)、教育程度(educ)與美國總統選舉(vote)的相關性,這些變數的數值編碼(coding)與分析結果如下。請問男性對比女性選民(Male vs. Female),投給 Trump(vote = 1 vs. 0)的勝算比為何?
vote
0 = ' Clinton '
1 = ' Trump ' ;
gender
1 = ' Male '
2 = ' Female ' ;
educ
1 = ' HS Not Completed '
2 = ' Completed HS '
3 = ' College <4 Years '
4 = ' College 4 Year Degree '
5 = ' Advanced Degree '

2024最新生物統計學測驗題精解勘誤
1.第34頁,第三章 常態分布、標準常態分布,第2題:
( B )2.某一統計學課程獲得成績A的同學每週(以五天計)花在讀統計學的時間服從常態分配,平均數為9小時,標準差為1.5小時。成績A的同學有10%每週讀統計學的時間不到a小時,另有10%每週讀書時間超過b小時,請問(a,b)的值為何? (A)(7.18,10.82) (B)(7.08,10.92) (C)(6.98,11.02) (D)(6.88,11.12)
解析:
從標準常態分配表查得: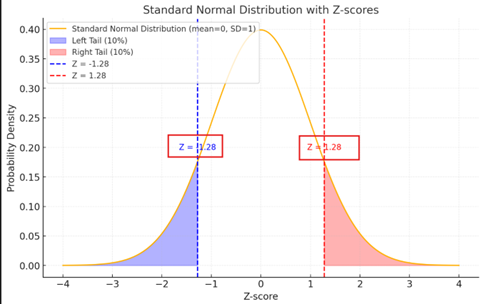
Z = -1.28,對應累積機率為 0.10。
Z = +1.28,對應累積機率為 0.90。
即,Ζ=±1.28
a=9-1.28×1.5=9-1.92=7.08
b=9+1.28×1.5=9+1.92=10.92
答案為(B)(7.08,10.92)
![]()
流行病學系列
流行病學測驗題精解(11107-v1)勘誤
|
頁數 |
修正題目 |
|
頁數:46 |
第34題 正確答案:(A)因果時序性不明,引起危險因子與疾病之致病關係性不明 |
|
頁數122 |
第63題-為詳解敘述中的答案。正確答案:(A)減弱 |
|
頁數141 |
第124題 正確答案:(B)在累乘模式(multiplcative modle)下為協同作用 |
|
頁數160 |
第38題 正確答案:(B)死亡率 |
|
頁數175 |
第87題 詳解改為80/(80+40)=0.66=66% |
流行病學測驗題題庫(11011-v1)勘誤

流行病學擬真試題(11106-v1)勘誤
第一回,#21題 #36題
( B ) 21.
下表為一探討糖精(artificial sweetener)與膀胱癌(bladder cancer)病例對照研究之研究結果。根據下表數據,計算曾經食用過糖精者罹患膀胱癌的勝算比 (odds ratio)值為 (A)0.3 (B)3 (C)0.5 (D)2
|
Artificial sweetener use |
Cases |
Controls |
Total |
|
Never |
100 |
300 |
400 |
|
Ever |
200 |
200 |
400 |
|
Total |
300 |
500 |
800 |
解析:注意!不要直接交叉相乘後相除,因為本題把從未(Never)使用糖精(非暴露組)的組別擺在暴露組上面。按照Odds ratio公式來算OR=病例組的暴露勝算/控制組的暴露勝算=(200*300)/(100*200)=3,答案為(B)。
( D ) 36.
請問下列何者正確? (A)嚼食檳榔者的口腔癌發生率為2/每千人年 (B)勝算比(odds ratio,OR)=(72*4000)/(8*5000) (C)相差危險性(risk difference,RD)=(72-8)/9000 (D)以上皆非
解析:嚼食檳榔口腔癌發生率=72/5000=14.4/每千人年 (A錯誤);應為RR,非OR(B錯誤);相差危險性(RD)=(72/5000)-(8/4000)(C錯誤); 所以答案為(D)以上皆非。
第二回,#3題 #8題
( C ) 3.
分析糖尿病新發生病患之年齡分佈,18%、25%、35%與 22%之病患分別發生於≤49、50-59、60-69 與≥70 歲之年齡群。下列何者敘述正確? (A) 60-69 歲的個案最容易發病 (B) 50-59 歲個案之發病率為25% (C) ≤49 歲個案之疾病百分比為18% (D) (A)與(C)
解析:注意本題的敘述!這是糖尿病新病人的年齡分布,不是各年齡層的發病率!因此(A)、(B)一定錯,(C)正確。
( B ) 8.
死亡率長期趨勢的研究中,因死亡分類的改變對死亡率造成的影響,通常為下述何者? (A)年齡效應 (B)年代效應 (C)出生世代效應 (D)人口老化效應
解析:本題關鍵概念為”死亡分類的改變”,即觀察長期多年的趨勢,在某年因死亡分類改變對死亡率造成影響。就是在特定時間點下,因某個因素存在,對全部人口造成改變,此為年代效應,因此答案為(B)年代效應。進一步說明三種時間效應:
- 「年齡效應」:年齡對生命的影響,又可稱為生命週期(Life cycle)。年輕時較激進,年老時較保守等。年齡對很多疾病的發生與死亡率有明顯影響。
- 「年代效應」:在特定時間點下,不分年齡的人們對某些價值觀特別高漲。如現在因為COVID-19流行,因此人們的防疫意識特別高。
- 「世代效應」:同一出生世代成員共享的獨特成長經驗,此經驗將標記他們的一生。
第三回,#24題
( C ) 24.
有關於配對(matching)之病例對照研究,下列描述何者錯誤? (A) 匹配因子必須是干擾因子 (B) 在病例對照研究中採用匹配的目的,是為了增加研究效率(efficiency) (C) 如果匹配因子是中間變項(intermediate variable),會高估相對危險性 (D) 被匹配的因子仍可以評估它與其他危險因子之交互作用
解析:若匹配的因子是中間變項,會形成過度匹配的問題,導致X與Y的相對危險性會被低估。因為匹配會將兩組的中介變項趨同,換句話說,有無暴露X的程度就會接近,因此沒法偵測出對Y的影響,造成低估危險性。(C)錯誤。
第四回,#10題
( B ) 10.
如果某一研究要檢定雌激素(estrogen)與子宮內膜癌的相關性,作者在統計分析時決定以單尾小於0.05 為具統計學差異,其假設為何? (A) 暴露比例呈常態分布 (B) 預期雌激素是子宮內膜癌的原因 (C) 雌激素是子宮內膜癌成直線相關 (D) 需避免第二類錯誤(type Ⅱ error)
解析:依據題意,以單尾小於0.05是有方向性的假設,亦即假設雌激素會促進子宮內膜癌的發生,答案為(B)預期雌激素是子宮內膜癌的原因。
第六回,#3題 #29
( D ) 3.
若在A、B兩族群某病的標準化死亡(standardized mortality ratio, SMR)分別為0.5及1.0,請問下列敘述何者正確 ? (A)A族群比 B族群較容易因此病而死亡 (B)B族群比 A族群較容易因此病而死亡 (C)A與 B族群因此病而死亡的機會一樣 (D)以上皆非
解析:標準化死亡比稱間接標準化死亡比。該指標用於比較兩組群之死亡狀況,通常會以人口數較大族群定義為標準族群,以標準族群之年齡別死亡率為基準,估計人口數較小族群之死亡人數(稱預期死亡人數),計算人口數較小族群實際死亡人數和預期死亡人數人之比值。如標準化死亡比為1表示,兩組群死亡狀況沒有差異,大於1表該族群死亡狀況高於標準族群,但須注意的不同標準化死亡比不可互相比較,因標準化死亡比並無調整年齡結構,例如埔心鄉105年不分疾病標準化死亡比為1.21(標準化死亡率為每十萬人口539.48人),線西鄉105年不分疾病標準化死亡比為1.19(標準化死亡率為每十萬人口553.27人),埔心鄉標準化死亡比1.21高於線西鄉1.19,但觀察兩鄉標準化死亡率,埔心鄉標準化死亡率低於線西鄉。因不同標準化死亡比不能互相比較,因此答案為(D)以上皆非。
( C ) 29.
利用世代研究設計進行病因學探討時,下列何者是研究設計上最主要的重點? (A) 暴露組與對照組的樣本數應該要相等 (B) 研究進行初始,有病的研究對象與沒病的研究對象應力求年齡等潛在干擾因子分布平均 (C) 所有的研究對象在研究開始前必須確定都未罹患研究所將探討的疾病 (D) 所有研究對象必須是來自族群的一個具有代表性樣本
解析:世代研究設計進行病因學探討時,必須要全部研究對象在研究開始前都未罹患研究所要探討的疾病,這樣才能計算發生率與相對危險性,來進行病因學探討。答案為(C)。
111-112年高等考試公共衛生師流行病學試題解析(2023.11)勘誤
1.第111年測驗題第18題,修正解析說明
下表是一個探討兩種抗血栓藥物(Aspirin, Warfarin)與發生缺血性心臟疾病的隨機對照試驗研究數據,包含四組治療組:安慰劑、單獨使用 Aspirin、單獨使用 Warfarin、合併使用 Aspirin 及 Warfarin,下列敘述何者錯誤?
|
治療組別 |
缺血性心臟疾病發生率/1000 人年 |
|
Double placebo |
13.3 |
|
Aspirin alone |
10.3 |
|
Warfarin alone |
10.2 |
|
Aspirin and Warfarin |
8.7 |
(A)單獨使用Aspirin會減少3.0/1000人年的缺血性心臟疾病發生率
(B)單獨使用Warfarin會減少3.1/1000人年的缺血性心臟疾病發生率
(C)Aspirin與Warfarin對缺血性心臟疾病風險有加成協同作用
(D)Aspirin與Warfarin對缺血性心臟疾病風險有加成拮抗作用
解析:
這個問題需要計算每種治療方案對於缺血性心臟疾病發生率的影響,並評估Aspirin和Warfarin的聯合使用是否顯示出任何形式的交互作用。
答案為(C) Aspirin與Warfarin對缺血性心臟疾病風險有加成協同作用。
以下為各選項解析:
(A) 正確。單獨使用Aspirin的組別的缺血性心臟疾病發生率為10.3/1000人年,相比於安慰劑組(Double placebo)的13.3/1000人年,降低了3.0/1000人年。
(B) 正確。單獨使用Warfarin的組別的缺血性心臟疾病發生率為10.2/1000人年,相比於安慰劑組的13.3/1000人年,降低了3.1/1000人年。
(C) 錯誤。如果Aspirin和Warfarin對風險減少具有加成作用,我們期望減少的發病率應該是兩者單獨減少的發病率之和,即:
預期減少的發病率 = 3.0/1000 + 3.1/1000 = 6.1/1000 人年
期望的發病率 = 13.3 - 6.1 = 7.2/1000 人年
實際發病率為8.7/1000 人年,高於期望值(7.2/1000 人年),表示兩者並未產生加成協同作用,反而是拮抗作用,即,合用的效果小於預期加成效果。因此,本選項錯誤。
(D) 不正確。詳解同上。因此,本選項正確。