
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司






在觀察性研究(Observational Study)中,變數選擇始終是研究者最常陷入的方法學陷阱之一。傳統作法──以單變項相關、顯著性、逐步回歸(Stepwise Regression),或「文獻常用變數」作為控制變數的依據──實際上處理的是統計關聯,而非因果結構(Causal Structure)。
本文以方法學文獻為憑據,論證一個核心命題:變數該不該放進模型,取決於它在因果結構中的角色,而非它與結果的統計相關強度。文中將援引 Shrier 與 Platt 在 BMC Medical Research Methodology 的方法學論文,以及 Feeney、Hartwig 與 Davies 於 BMJ 發表的臨床研究指引,系統說明干擾因子(Confounder)、中介變數(Mediator)、碰撞因子(Collider)三類變數在因果推論(Causal Inference)上之本質差異。
本文同時介紹有向無環圖(Directed Acyclic Graph, DAG)作為一套讓隱含假設公開化的方法論工具,並透過三類最常見的誤用情境,說明為何「越調整不一定越準」、為何相同變數在不同研究問題下,有時該控制、有時必須放手。本文的目標讀者是醫學研究者、流行病學家與統計顧問實務工作者,期能為觀察性研究之變數選擇提供一套以因果邏輯為核心之判斷框架。
I問題的起點──觀察性研究的變數選擇困境
幾乎每一位從事觀察性研究的醫學研究者,都曾在分析計畫的擬定階段遭遇同一個問題:「這個變數,究竟該不該放進模型?」當資料中可用的變數數以十計,而每一個變數又都看似與結果(Outcome)有那麼一點關聯時,研究者往往訴諸最直覺、最廣為流傳的策略──看單變項分析的相關性、看 p 值、執行一輪逐步回歸(Stepwise Regression),或乾脆引用「文獻上大家都這樣放」作為判準。此套作法在學術期刊中如此普遍,以致幾乎已成為一種隱性的方法學規範。
然而,此套規範背後其實隱藏著一個未被檢驗的前提:變數與結果之間「有相關」就等於「應該被控制」。此一前提乍看合理,實際上卻是一個危險的心智模型。它把統計層次的關聯(Association)與因果層次的調整需求混為一談,從而讓研究者在尚未釐清因果結構的情況下,就匆忙地以統計工具去回答因果問題。換言之,研究者所操作的,是一場以統計表現為依據、卻冠上因果語言的推論遊戲。
關鍵概念|因果結構(Causal Structure)
所謂「因果結構」,係指研究中各變數之間真實的因果關係網絡──誰是誰的原因、誰是誰的後果、誰扮演中介角色、誰由共同來源產生。任何回歸、配對或分層分析,事實上都建立在一套關於因果結構的隱含假設之上,只是此等假設往往沒有被研究者明確寫出來。
因果結構之中,某一個變數可能扮演的角色不只一種。首先,它可能是干擾因子(Confounder),亦即同時影響暴露(Exposure)與結果的共同原因,此類變數若不調整,將導致估計值偏移。其次,它可能是中介變數(Mediator),位於暴露對結果的因果路徑之上,代表著暴露之所以會影響結果的中介機制。再者,它可能是碰撞因子(Collider),亦即由兩個或多個變數共同影響的「下游節點」,此類變數一旦被條件化,將打開原本不存在的非因果關聯。最後,它也可能只是某個變數的後代節點(Descendant),亦即某真實因果節點的下游量測代理變數,其控制效果取決於它所代表的母節點。
此四種角色在統計表現上,往往看不出明顯差別。它們可能都與結果有相關,也都可能在單變項分析中顯著。然而,從因果推論的角度來看,它們對應到的處理策略卻是截然不同──有些必須調整,有些絕對不能調整,有些則必須先釐清研究問題本身才能決定。若研究者僅以相關性作為篩選依據,結果便可能是漏掉真正該調整的干擾因子、誤調整中介或碰撞因子、打開原本關閉的偏差路徑,並讓估計值「更偏,而不是更準」。
變數選擇之關鍵,不在於它與結果的統計相關有多強,而在於它在因果結構之中扮演何種角色。不同角色對應到截然不同之處理策略,以單一相關性指標作為判準,等同於用統計工具去回答因果問題,結果往往導致估計值更偏。
II文獻的警示──傳統方法的方法學侷限
傳統觀察性研究中所採用的變數選擇策略,大致可歸納為四種典型路徑:其一,以單變項分析的顯著性為門檻;其二,以「換入或移除某變數後估計值改變超過 10%」作為干擾因子的判準;其三,藉逐步回歸自動篩選變數;其四,直接沿用前人文獻中常見的調整變數清單。此四種策略在當代統計教學中仍被廣泛傳授,並被許多臨床期刊視為合理的方法學標準。然而,過去二十年的方法學文獻已逐步指出,此等策略之共同問題在於──它們處理的全部是「統計關聯」此一層次的問題,卻被誤用以回答「因果效應」此一層次的問題。
Shrier 與 Platt 在其 2008 年發表於《BMC Medical Research Methodology》的方法學論文中,對此一錯置問題提出極具份量的警告:
"The traditional methods of adjusting for 'potential confounders' may introduce conditional associations and bias rather than minimize it."
— Shrier I, Platt RW. BMC Med Res Methodol. 2008;8:70.(詳見文末參考文獻 1)
此一論點的核心,並非否定所有干擾因子的調整,而是揭示一個更為基本的事實:傳統的調整方法之所以可能製造而非減少偏差,正是因為它將判斷依據建立在統計關係之上,而非建立在變數於因果結構中所扮演的角色之上。當研究者僅以「看到相關就調整」、「納入模型讓統計自行篩選」、「只要與結果有關就先放」等策略行事時,他所引入的不是干擾的去除,而是 Shrier 與 Platt 所稱的「條件化關聯(Conditional Association)」──亦即一種因為錯誤條件化所產生、原本並不存在的虛假關聯。
值得注意的是,Shrier 與 Platt 在同一篇論文中進一步明確界定生物醫學研究的核心目標,並以此區辨統計問題與因果問題之根本分野:
"The objective of most biomedical research is to determine an unbiased estimate of effect for an exposure on an outcome, i.e. to make causal inferences about the exposure."
— Shrier I, Platt RW. BMC Med Res Methodol. 2008;8:70.(詳見文末參考文獻 1)
此處的關鍵在於:絕大多數生物醫學研究真正想回答的,並非「在資料中,X 與 Y 是否有統計相關」此類描述性問題,而是「如果暴露 X 改變,結果 Y 會如何變化」此一因果問題。前者屬於統計學的範疇,後者則屬於因果推論(Causal Inference)的範疇──兩者使用相似的數學工具,卻有著根本不同的判讀邏輯。當研究者以統計篩選方法去回答因果問題時,工具與目標之間的錯置便成為偏差的主要來源。
因此,若研究目標是估計暴露對結果的因果效應,變數選擇的判準便不應只看「它與結果是否相關」,而必須回到一個更根本的問題:它在因果結構中位於哪一條路徑、扮演哪一個角色?要系統化地回答此一問題,我們需要一套讓因果假設可被攤開、可被檢視、可被同儕質疑的方法論工具。而這,正是有向無環圖之所以被引入流行病學與生物統計領域的原因。
傳統的「相關即調整」策略之所以可能製造偏差,根源在於它將統計關聯的判準誤用於因果問題。Shrier 與 Platt 的論證提醒我們:生物醫學研究之核心目標是因果推論,而要服務於因果推論,變數選擇必須回到因果結構之層次。
IIIDAG 方法論的價值──把隱含假設攤開來
有向無環圖(Directed Acyclic Graph,DAG)為當代因果推論方法論中最具影響力的圖形語言之一。它的核心並非「將研究流程畫成漂亮的示意圖」,而是將原本只存在於研究者腦中的因果假設,以一種公開、結構化、可被同儕檢視的方式表達出來。一張 DAG 不只描繪「誰指向誰」,它同時也決定哪些路徑是因果路徑(Causal Path)、哪些是後門路徑(Back-door Path)、哪些變數一旦被條件化會打開非因果關聯,以及──最關鍵的──為了估計某個因果效應,究竟需要(或不能)調整哪些變數。
關於 DAG 方法論的本質,Shrier 與 Platt 在其論文中有一段極為精準的論述,值得完整引用:
"In other words, the DAG representing the true causal structure exists even if we do not know what it is, and all causal inferences based on statistical models are implicitly based on a causal structure – the DAG approach simply makes the assumptions explicit."
— Shrier I, Platt RW. BMC Med Res Methodol. 2008;8:70.(詳見文末參考文獻 1)
此段論述蘊含一個深刻而往往被忽略的事實:不論研究者是否畫出 DAG,只要他在執行回歸、配對、傾向分數或分層分析,他就已經默默地在使用某一套因果結構假設。換言之,因果假設並非「畫了 DAG 之後才存在」,而是任何因果性聲稱所必然蘊含的前提。研究者選擇不畫 DAG,並非「擺脫了假設」,而是讓那些假設停留在隱性、未被檢驗、不可挑戰的狀態。
DAG 方法論真正的價值,因此並不在於它提供某種「更正確的答案」,而在於它強迫研究者把假設攤開來。一旦因果結構被明確繪製,研究者便能依據圖形拓撲規則(如後門準則 Backdoor Criterion)系統化地判斷:為了估計暴露 X 對結果 Y 的因果效應,哪些路徑必須被關閉、哪些路徑絕對不能關閉、哪一個變數集合構成最小充分調整集(Minimal Sufficient Adjustment Set)。此套判斷不再依賴研究者的個人經驗,也不再受制於統計篩選方法的隨機性,而是奠基於明確、可被質疑、可被修改的因果假設之上。
總而言之,DAG 與傳統統計調整策略之根本差異,在於兩者所處理的問題層次完全不同。傳統策略試圖回答「在資料中,加上此一變數後 R² 增加多少、估計值改變多少」;DAG 方法論則回答「依據我所繪製的因果結構,特定變數是否會打開或關閉某條路徑」。前者是描述性的,後者是結構性的;前者由資料驅動(Data-driven),後者由假設驅動(Hypothesis-driven);前者輸出的是統計指標,後者輸出的是調整集合(Adjustment Set)。理解兩者間處理的層次差異,為進入 DAG 方法論的第一道門檻,也是判讀後續所有變數選擇爭議的基礎。
DAG 並未為因果推論引入新的假設,它只是強迫研究者把原本就在使用、卻未被寫明的假設攤開來。其價值不在於提供更漂亮的圖示,而在於提供一套讓因果假設可被檢視與挑戰之結構化語言。
IV三類常見誤用情境
在實務研究中,變數選擇的失誤雖然形式多樣,卻往往可歸納為三類最具代表性的情境。第一類,是研究者把「對結果具有強預測力」的變數,直接等同於「應該被控制的變數」;第二類,是研究者調整了一個碰撞因子,從而打開了原本並不存在的非因果關聯路徑;第三類,則是研究者在估計總效果時,誤將位於因果路徑上的中介變數納入模型,導致回答的問題已經偏離原本的研究設定。以下分別說明此三類誤用情境之內在邏輯與其在因果結構上的根源。
情境 4.1|把「預測重要」誤當成「應該控制」
第一類誤用發生於研究者面對「看似很重要」的變數時。在臨床研究中,某些變數──例如疾病史、檢驗指標、疾病嚴重度評分──確實在單變項分析中與結果高度相關,並在預測模型中具有不容忽視的解釋力。研究者於是憑直覺認為:「既然它這麼重要,就應該放進模型控制。」然而,此一直覺混淆兩個本質不同的問題──「預測」與「因果」。
所謂高預測力,意味著該變數的數值能夠協助我們在已知資料中推估結果的可能值。但這並不等同於該變數位於暴露對結果的因果路徑之外、且為兩者的共同原因。事實上,一個與結果高度相關的變數,可能是暴露對結果之中介機制的下游量測;可能是某個碰撞因子的後代節點;也可能是研究選擇機制(如住院、轉診、或某種篩檢)所產生的條件化節點。在此等情境下,將其納入模型非但無助於減少偏差,反而可能引入額外的條件化關聯。
上述情境之根本啟示在於:預測建模(Predictive Modeling)與因果效果估計(Causal Effect Estimation)所遵循的變數選擇邏輯,本質上是兩種不同的工作。前者追求模型在驗證資料上的預測準確度,因此鼓勵納入所有與結果有關的變數;後者追求暴露對結果之因果效應的無偏估計(Unbiased Estimate),因此必須依據因果結構而非統計表現來決定變數。若研究目的是因果推論,卻沿用預測建模的變數選擇思維,等同於用錯誤的工具去做對的事情。
「預測重要」與「應該控制」是兩個層次的問題。預測模型由資料驅動,因果效應估計由因果結構驅動;若研究目標是後者,就不能用前者的選變數邏輯。
情境 4.2|調整碰撞因子,打開假路徑
第二類誤用涉及碰撞因子(Collider)──此為 DAG 方法論中最具教學價值、也最容易被傳統統計訓練忽略的一類變數。所謂碰撞因子,係指一個變數是兩個(或多個)變數的共同結果(Common Effect)。以最簡單的三節點結構為例:當 X 與 U 各自指向 C(亦即 X → C ← U),C 即為 X 與 U 的碰撞因子。在此一結構之下,若我們不對 C 做任何條件化,X 與 U 之間的路徑是「關閉的」──兩者並無非因果關聯。
然而,一旦研究者透過迴歸調整、分層,或匹配等方式,將 C 條件化(亦即「控制」C),原本封閉的 X ↔ U 路徑就會被「打開」,使得 X 與 U 之間在條件化後出現一種原本並不存在的非因果關聯。Feeney、Hartwig 與 Davies 在其 2025 年發表於《BMJ》的臨床研究指引中,對碰撞因子提出精準而具操作意義的定義:
"A variable that is a common consequence of two variables that, if conditioned on (eg, through regression adjustment, stratification, or matching), can open a non-causal path of association between the exposure or treatment and the outcome of interest."
— Feeney T, Hartwig FP, Davies NM. BMJ. 2025;388:e078226.(詳見文末參考文獻 2)
此一定義之所以重要,在於它將「條件化會發生什麼事」此一問題從直覺層次提升到方法論層次。傳統訓練告訴研究者「相關就調整」,但 DAG 方法論告訴我們:對於一個與暴露及未量測干擾源有共同結果關係的變數,調整它非但不會減少偏差,反而會在原本無關的兩個變數之間製造出一條虛假的關聯路徑。此即所謂的「碰撞偏差(Collider Bias)」,也是當代流行病學中最常被援引的一類選擇偏差來源。
下方兩張 DAG 圖以最簡明的方式對比「未控制 C」與「控制 C」的差異:
圖 4.1|未控制 C(路徑關閉)
路徑 X → C ← U 關閉,X 與 Y 之間無非因果關聯。此為碰撞結構的「自然封閉狀態」。
圖 4.2|控制 C(打開偏差路徑)
條件化 C → 打開 X ↔ U 路徑 → X 與 Y 之間出現非因果關聯,即典型的碰撞偏差。
情境 4.3|調整中介變數,改變研究問題
第三類誤用涉及中介變數(Mediator),亦即位於暴露對結果之因果路徑上的中間節點。中介變數所代表的,正是暴露之所以能夠影響結果的「機制」──例如肥胖之所以提升死亡風險,可能透過代謝異常、慢性發炎、心血管事件等中介機制逐步傳遞其因果效應。在此類研究中,中介變數既與暴露高度相關,也與結果高度相關,因此在統計篩選方法之下,它幾乎必然會被選入模型。然而,將中介變數放入模型,究竟是減少了偏差、還是改變了問題本身,卻取決於研究者真正想回答的因果效應類型。
關於此一要點,Shrier 與 Platt 提供了一段方法論上極為清楚的論述:
"Although researchers should generally not adjust for a covariate (or a marker for a covariate) that lies along a causal pathway when assessing the total causal effect, this may not be the case for researchers interested in decomposing total causal effects into direct and indirect effects."
— Shrier I, Platt RW. BMC Med Res Methodol. 2008;8:70.(詳見文末參考文獻 1)
此段論述的精妙之處,在於它將中介變數的「該不該調整」問題,轉化為「研究問題本身是什麼」的問題。如果研究者想估計的是總效果(Total Effect)──亦即暴露透過所有可能管道對結果產生的整體影響──那麼任何中介變數都不應被納入模型,因為將中介條件化等同於「拿掉了暴露之所以會影響結果的部分機制」,所得到的估計值便不再是總效果。反之,若研究者所關注的是直接效果(Direct Effect)──亦即暴露不經過某些特定中介機制所產生的影響──那麼針對該中介的條件化,反而是回答此問題的必要手段。
換言之,中介變數的處理並無絕對的「對」或「錯」,只有「與研究問題是否相符」此一判準。當研究者在報告中宣稱估計「肥胖對死亡的影響」時,他必須清楚地告訴讀者:此一「影響」是包含所有中介機制的總效果,還是排除特定中介之後的直接效果?兩者具有截然不同的因果意義,而能夠協助研究者在分析之前做出此項判斷的工具,正是 DAG。
中介變數之處理沒有絕對對錯,但有研究問題是否相符之問題。若研究目標是總效果,則不應調整中介;若目標是直接效果,則必須調整。研究者必須先回答自己想問的是哪一種效果,才能決定變數之去留。
V結語|變數選擇的因果邏輯,決定研究問題的答案
回顧本文的論證脈絡,我們可以看出一個一以貫之的核心主張:觀察性研究中之變數選擇問題,本質上不是統計問題,而是因果問題。當研究者意識到此一要點之後,許多原本看似「該找更進階統計方法解決」之困境,其實都可以被重新定位為「該先把因果結構釐清」之方法學前置工作。換言之,許多分析上的困擾,並非出在估計工具不夠精巧,而是出在因果邏輯尚未先行被攤開、被檢視、被同儕質疑。
有向無環圖並非萬靈丹,它無法替研究者決定哪一個因果結構才是「真正正確」的。事實上,一張 DAG 的價值,並不取決於它是否「畫對了」,而取決於它是否將所有研究者所依賴的假設,以一種公開、結構化、可被同儕修改的方式呈現出來。研究團隊可以對同一個研究問題畫出多張 DAG,反映不同的理論立場或文獻證據;他們也可以在同行審查中根據新的證據修改 DAG。重要的是,所有的調整與爭辯都發生在因果結構此一層次,而不再被混雜進「哪個變數的 p 值較低」此類無關之統計判準之中。
對於從事臨床研究、流行病學研究或統計顧問實務的工作者而言,熟練 DAG 方法論並非一項額外的技能,而是一項基本的方法學素養。它讓我們能夠在分析啟動之前,就先回答最關鍵的問題──「我究竟想估計的是什麼?為了估計此一量,我必須調整哪些變數?哪些變數又絕對不能調整?」唯有先回答此等因果層次的問題,後續的統計分析才能真正地服務於研究目標,而非讓研究目標被工具反過來牽著走。
從方法論到實作
本文所闡述的因果結構觀點與 DAG 方法論,僅是進入此一研究典範的起點。若您希望系統化地學習如何從研究問題出發繪製 DAG、如何辨識干擾、中介與碰撞因子、如何避免「越調整越偏」的常見陷阱,以及如何運用 DAGitty 等工具找出最小充分調整集(Minimal Sufficient Adjustment Set),我們誠摯邀請您參考匯東華統計學院新上市之線上錄製課程「這個變數該不該控制?DAG(Directed Acyclic Graphs)一畫就知道」。本課程將以實際醫學研究案例為核心,帶領學員一步一步將因果思維轉化為可操作的方法論工具。
參考文獻
-
Shrier I, Platt RW. Reducing bias through directed acyclic graphs. BMC Med Res Methodol. 2008;8:70.
DOI: 10.1186/1471-2288-8-70 -
Feeney T, Hartwig FP, Davies NM. How to use directed acyclic graphs: guide for clinical researchers. BMJ. 2025;388:e078226.
DOI: 10.1136/bmj-2023-078226
本文撰寫過程中,感謝匯東華統計顧問有限公司智慧體部智澄辰(Claude Opus 4.6)協助進行內容整理與 HTML 結構化。最終內容已由作者審閱並修訂定稿。日期:2026 年 4 月 9 日。
聯絡我們
- LINE:@medatatw
- Email:info@medatatw.com
- 電話:07-9721586
- 官網:www.medatatw.com
![]()
統計分析
服務價目表 (未含5%營業稅)
透過嚴謹的數據整理,提供有價值的資訊,形塑知識,提高決策品質。包括信達雅三執行原則。
信:確保資料品質可信賴
達:確保統計方法適切性
雅:確保圖文表格正規化
協助代執行統計分析與進一步加值服務。
在匯東華與夥伴的專業背景知識配合下,能有效地處理面對的問題。
統計分析成果
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。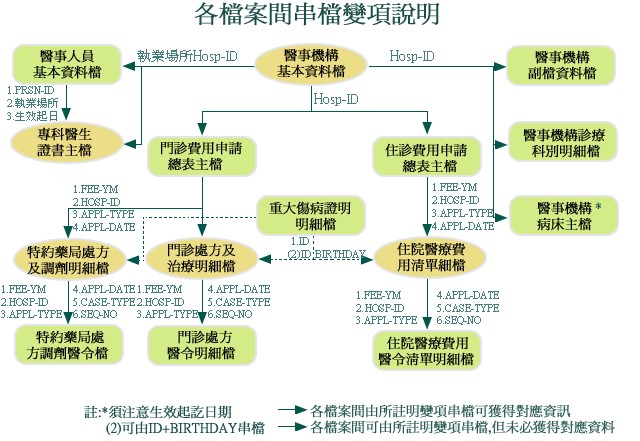
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
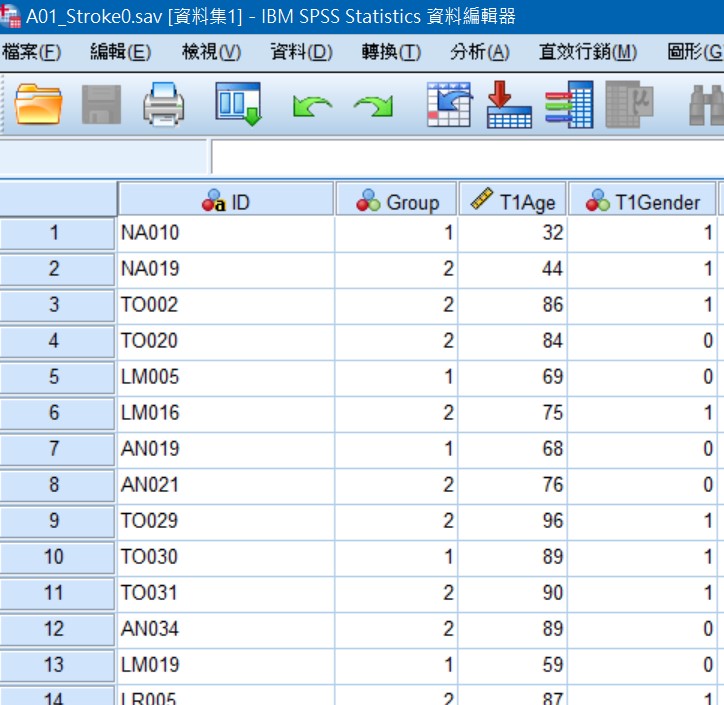
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖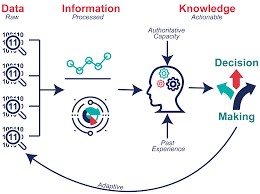
![]()
計畫撰寫與統計諮詢


為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。
