
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
BMJ小小統計問題(90):Standard deviation or the standard error of the mean (標準差或平均值的標準誤)
Cite this as: BMJ 2015;350:h831
https://www.bmj.com/content/350/bmj.h831.long
前言
原來已經到90期了,在不知不覺間,多少個日日夜夜,維持每周一期的頻率,90期,90周,代表原來已經過了一年7個多月。然後,不知不覺,繼續前進就到100期、200期、30期…
很多事情,規劃好,選定方向,就開始進行,成功或失敗也不用太在意,自己喜歡就好。
標準差與標準誤是統計中非常基本的兩個概念,是機率描述以及推論的基礎,也是讓很多人頭痛的點。本期內容與第#80期Standard deviation versus standard error (標準差和標準誤)可以一併參照閱讀,是解痛良方。
✅匯東華2023秋、冬季課程與工作坊日期即將公告
✅5/20「ChatGPT於科學研究之應用」:活用ChatGPT`:六大研究應用場景實戰,熱烈報名中!
✅5/27「WS3-SPSS醫學研究統計工作坊:配對研究設計與分析」,熱烈報名中!
詳細資訊請上匯東華官網/課程報名
精彩可期,歡迎報名!
問題
研究妊娠期低血糖指數飲食對有巨大嬰兒(大於胎齡)風險的孕婦和新生兒發病率的影響。進行隨機對照試驗。介入包括從妊娠早期開始的低血糖指數飲食。對照組不進行飲食介入。參與者均為無糖尿病的女性,都是第二次懷孕,以前生過體重超過4000克的嬰兒。總共招募800名婦女,並隨機分為介入組(n=394)和對照組(n=406)[1]。
治療組的基線特徵包括身體質量指數(BMI)(介入:平均值26.8(標準差5.1);對照26.8(4.8))。結果測量包括出生體重和妊娠體重增加。介入組的婦女中,372人完成追蹤中,而對照組的婦女則有387人完成追蹤。使用 per protocol analysis (Showme:可參閱# BMJ統計問題(23))。介入組之平均出生體重高於對照組,但差異不顯著(平均4034(標準誤26.4) vs 4006 (25.3) g;平均差異為28.6 g, 95%信賴區間- 45.6 ~ 102.8;P = 0.449)。介入組平均妊娠體重增加明顯較少(12.2(標準誤0.23)vs 13.7 (0.25) kg;平均差- 1.35 kg, - 2.45 ~ - 0.24;P = 0.01)。研究人員得出結論,懷孕期間低血糖指數飲食並不能顯著降低嬰兒的出生體重,但對於有巨大嬰兒風險的婦女來說,會顯著減少妊娠體重增加。
下列敘述何者正確?(複選)
a) BMI的標準差量化分配到不同治療組樣本成員在基線時測量值的變化
b)出生體重的標準誤量化母群體中出生體重測量值的變化
c)在基線時,約66%的樣本成員BMI在樣本平均值的一個標準差範圍內
d)若樣本量增加,則標準誤的大小預計會減小
答案
a, c和d正確,b錯誤。
詳細說明
a, c和d正確,而b錯誤。標準差和標準誤差經常被混淆。標準差用於描述樣本數字的變數測量值之變化(a正確)。標準誤為將樣本平均值作為描述母群體參數,即母群體平均值估計值之精確程度(b錯誤)。如,標準誤有時被稱為平均值的標準誤,用於使用信賴區間對母群體參數進行推論。兩者應用情境為:標準差用於描述,標準誤用於估計。
該試驗目的是確定懷孕期間低血糖指數飲食對有巨大嬰兒風險的孕產婦和新生兒發病率的影響。採用隨機對照試驗研究設計。隨機化目的是為了獲得基線特徵相似的組別,從而最大限度地減少干擾。為了評估隨機化過程是否成功,研究人員對介入組和對照組的基線特徵進行了描述性統計。各治療組採用目視檢查而非統計學顯著性檢驗進行比較。隨機化預計會產生具有相似基線特徵的治療組,因此統計假設檢定通常被認為是不合適的,因為它有可能出現I型錯誤(type I error),並可能產生誤導性的結果[2-3]。提供基線特徵的描述性統計資料允許讀者評估試驗結果是否可以概化到臨床實務之病人。
基線特徵包括BMI。BMI的樣本標準差量化了BMI的變化——特別是,對於每個治療組,它提供了樣本成員的平均BMI與基線時樣本平均BMI的變化程度(a正確)[4]。基線時BMI的樣本標準差可用於計算BMI的範圍,其中包含樣本成員的近似百分比。通常推導出三個範圍。如,對於介入組,大約68%的樣本在基線時的BMI與樣本平均值的距離位於正負一個樣本標準差內,即在(26.8-5.1;=21.7)和(26.8+5.1);= 31.9)。此外,大約95%的介入組在基線時的BMI與樣本平均值的距離不超過兩個樣本標準差,即在(26.8−2(5.1)之間;=16.6)和(26.8+2(5.1);37.0)。最後,大約99%的介入組在基線時的BMI與樣本平均值的距離不超過3個樣本標準差,即在(26.8−3(5.1)之間;11.5)和(26.8+3(5.1);42.1)。
上述三個範圍的推導是基於常態分佈的性質[5]。對於在連續尺度上測量的任何變數,都能推導出這些範圍,只要樣本變數的分佈非呈偏態。通常只考慮基於一個和兩個樣本標準差的範圍。每個範圍中包含的樣本成員的比例為近似值。基於此,作者經常說,在基於兩個樣本標準差的範圍內包括約三分之二(66%),的樣本個數,而不是68% (c正確)。毫無疑問,三分之二比68%更容易記住。基於兩個樣本標準差的範圍通常用於推導常態範圍[6]。有時可以用所得的範圍來確定某變數的測量分佈是否偏斜。尤其是,若一個範圍的下限是不允許的或不太可能的,表明測量的分佈向右傾斜(正偏態)[7]。
上述試驗結果包括出生體重。樣本的平均出生體重是母群體參數之估計值,每個治療組估計不同的母群體參數。母群體參數是在抽取樣本的母群體中所有母親接受介入或對照治療時所看到的平均出生體重。雖然平均出生體重之樣本估計值在大小上與母群體參數相似非常重要,但它不太可能完全相等。樣本估計中的任何不準確都是基於母群體中母親的樣本——亦即,它可能是由抽樣誤差引起的。樣本平均出生體重作為母群體參數估計值的準確性由平均值的標準誤來量化。治療組的平均值標準誤由出生體重的樣本標準差除以治療組樣本量的平方根得出。因此,一般來說,若樣本量增加,平均值的標準誤大小預計會減小(d正確)。因為當治療組的樣本量接近母群體的樣本量時,樣本平均值的值將更接近母群體平均值,從而成為對母群體參數的更準確估計。
各組間平均出生體重差值為28.6 g,為母群體平均出生體重差之樣本估計值。平均值差的標準誤推導方法與上述樣本平均值標準誤的推導方法類似。對於每個治療組,樣本變異數除以樣本量後將結果值加在一起,該值的平方根等於平均差的標準誤。使用平均差的標準誤來推導出生體重平均差的母群體參數之信賴區間。信賴區間是母群體參數之區間估計,它量化了樣本平均出生體重差異作為母群體參數估計的準確性。在信賴區間上附加一個百分比,通常為95%。母群體出生體重平均差異的95%信賴區間為樣本出生體重平均差異兩側的1.96標準誤區間,即從(28.6−1.96(37.86);=−45.6 g) ~ (28.6+1.96(37.86);102.8 g)。可以推斷,信賴區間包含母群體參數的機率為0.95(95%)。如上所述,可以推導出樣本平均值加上樣本均值差的標準誤。還可以計算其他類樣本估計值的標準誤,包括比例、兩個比例間的差異、相對風險和勝算比。每個估計值的標準誤與上面描述的方法類似,用於得出母群體參數的95%信賴區間。
Reference:
[1] Walsh JM, McGowan CA, Mahony R, Foley ME, McAuliffe FM. Low glycaemic index diet in pregnancy to prevent macrosomia (ROLO study): randomised control trial. BMJ 2012;345:e5605.
[2] Sedgwick P. Randomised controlled trials: balance in baseline characteristics. BMJ 2014;349:g5721.
[3] Sedgwick P. Pitfalls of statistical hypothesis testing: multiple testing. BMJ 2014;349:g5310.
[4] Sedgwick P. Describing the spread of data I. BMJ 2010;340:c1116.
[5] Sedgwick P. The normal distribution. BMJ 2012;345:e6533.
[6] Sedgwick P. Normal ranges. BMJ 2013;346:f1343.
[7] Sedgwick P. Skewed distributions. BMJ 2012;345:e7534
#BMJ #醫學統計 #Standarderror #Standarddeviation #匯東華 #95%信賴區間
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖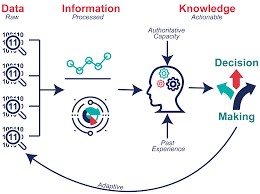
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


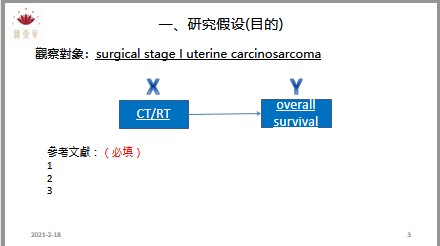
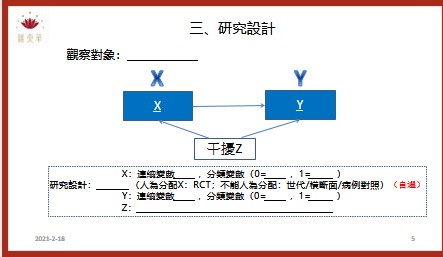
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。