
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
BMJ小小統計問題(65):
A comparison of parametric and non-parametric statistical tests (母數與無母數統計檢定的比較)
前言:
承接上期討論的母數 v 無母數檢定法的比較,本期同樣在整理這二種方法的異同之處,以及優劣勢進行更完整的說明。Hope u enjoy it.
匯東華自9月份開始,陸續將公司作業自動化、數位化,目前已初見成效。人力對匯東華而言是最珍貴的資源,因此,如何讓匯東華的同仁能夠在友善的工作環境下工作,除了賺錢之外,還能成長與享受生活一直是公司努力的目標。願每個人都能被這個世界溫柔以待。公司本周開始將陸續推出實用的統計分析套餐,將秉持專業、效率以及更親民平實的價格回饋給匯東華的支持者。
2022年Q4:智慧化的匯東華,第一步 進行中!
題目:
研究人員調查皮質類固醇在減少34-36周妊娠嬰兒呼吸系統疾病方面的效果。進行隨機對照安慰劑試驗。介入組是在懷孕34-36周時,連續兩天使用貝他每松(betamethasone),每日12 mg肌肉注射。參與者是320名懷孕34-36周且有早產風險的婦女。女性被隨機分配到介入組(n=163)或安慰劑組(n=157) [1]。
主要結局為新生兒呼吸障礙之發生率,包括呼吸窘迫綜合症與短暫性呼吸急促。次要結果包括嬰兒的圍產期測量,包括出生體重,加上5分鐘的Apgar score。統計假設採用雙尾檢定,臨界顯著性水準為設為0.05(5%)。分佈假設在統計檢定前得到驗證。介入組的呼吸窘迫綜合症發生率高於對照組(2例(1.4%) vs 1例(0.8%)),儘管差異不顯著(P=0.54),同樣地,短暫性呼吸急促發生率(34例(24%) vs 29例(22%); P = 0.77)也不顯著。介入組母親所生嬰兒的平均出生體重較高,但差異不顯著(2640(SD 445) v 2627 (452) g; student t test P=0.80)。介入組和對照組在5分鐘的Apgar評分沒有差異(中位數9 ( IQR 9-10) vs 9 (9-10); Mann-Whitney U test P=0.77)。
研究人員得出在懷孕34-36周時進行皮質類固醇的產前治療並無法減少新生兒呼吸系統疾病之發病率。
下列敘述何者正確?
a)使用Student 's t test假設每治療組之出生體重在母群體中呈常態分佈。
b) 在使用Mann-Whitney U test前,須假設個治療組母群體在5分鐘時Apgar評分的變異數相等。
c)無母數檢定可用於分析在連續或序位尺度上測量的資料。
d)在檢定組間平均出生體重差異方面,student t test比Mann-Whitney U test具有更佳的統計檢力 (power)。
答案:
a、c和d正確,而b錯誤。
詳細說明:
本研究的目的為測試皮質類固醇在減少34-36周妊娠嬰兒呼吸系統疾病方面的效果。進行隨機對照安慰劑試驗。傳統的統計假設檢定用於確定治療組之間是否存在圍產期測量的差異,因此對治療和主要結局間的關係造成干擾[2]。
有兩大類統計方法被使用-母數分析與無母數分析。當使用母數分析時,需對資料的分佈進行假設,而當使用無母數分析時不需要作這樣的假設。無母數方法有時被稱為無分佈法(distribution-free methods)或排序法(rank method)。在比較兩獨立群體時,通常使用母數法中的Student’s t test,而可以使用的無母數法則為Mann-Whitney U test或Wilcoxon rank sum test (魏克森等級和檢定)。
使用Student’s t test (也稱為獨立樣本t test)對治療組別的平均出生體重進行比較。Student’s t test為比較兩個獨立組別在連續尺度上所測量變數之平均值[3]。該檢定是一種母數法;此類方法假設所分析的變數在母群體中具有特定的分佈,通常是常態分佈。常態分佈是用平均值和標準差描述的理論分佈[4]。特別地,student’s t test的應用假設每治療組的出生體重在母群體中的分佈是常態的(a正確)。進一步的假設是,在母群體中治療組的出生體重變異數是相等的。
[Showme說明:使用母數分析前需確定要分析的變數是否符合常態性與變異數同質性]
通過對樣本出生體重的測量,驗證母群體出生體重呈現常態分佈的假設。可以使用正式的統計檢定,但它不一定都是準確的。因此,一般建議通過檢查每個治療組樣本測量的直方圖(histogram)來證實這一假設。
[Showme提醒:注意是使用直方圖,不是長條圖來檢視資料分佈是否為常態]
如果一個變數的分佈不是極偏斜的,則可以假定該變數的分佈是常態的。儘管如此,獨立樣本t test在偏離正常值方面非常穩健,特別是在兩組參與者數量相似的情況下。若樣本資料的分佈是傾斜的,那麼數值轉換——例如對數轉換 (logarithmic transformation)——可能使資料適合使用母數法進行分析[5]。母群體中治療組間出生體重變異數相等之評估將通過樣本標準差的比較得到驗證。最常使用的統計檢定方法——如,統計軟體常規提供的Levene’s test——將會被使用。然而,根據經驗,若較大的標準差與較小的標準差比值不超過2,則變異數將被視為相等。然而,如果變異數不相等,則軟體通常會在進行檢定的應用程式中做出調整。雖然對於兩治療組來說,出生體重的變異數相等並非必要的,但重要的是在統計檢定前對變異數的同質性進行調查。若假設不能被驗證,則應該使用無母數分析法,如下所述。
[Showme說明:兩獨立樣本t檢定同時具有假設變異數同質與不同質情況下的計算公式,因此,上段才會說對兩組平均數比較時,變異數需相等並非必要的前題假設。但,由於在判斷需要採用哪個t檢定公式前,還是需要先確認兩組變異數是否同質,因此,仍要先使用Levene’s test檢定變異數是否具備同質性。]
五分鐘時Apgar score按序位進行測量;因此,不能做出常態性的分佈假設,也不能使用Student’s t test。取而代之的是Mann-Whitney U test——student’s t test對應的無母數分析。無母數分析方法不要求對資料的分佈或母群體中組間變異數的相等性作假設(b錯誤)。雖然無母數方法不對資料的分佈做假設,但資料可能有一個特定的分佈,但並非所關注的重點。
無母數法仍然使用傳統的統計假設檢定;Mann-Whitney U test包含需無假設,即在母群體中每個治療組的五分鐘時Apgar score的分佈是相似的。Mann-Whitney U test基於對每治療組樣本的五分鐘時Apgar score得分進行排序。在需無假設下,若母群體中每治療組的Apgar score分佈相似,則樣本治療組評分的平均等級應該相等。Wilcoxon rank sum test有時會用來代替Mann-Whitney U test。此亦為無母數分析法,兩個檢驗會得到相同的P值,因此在統計假設檢定方面可以得出相同的結論。
如上所述,當使用母數法時,必須假設組別間要比較的變數在母群體中是常態分佈。因此,母數法只能用於分析連續尺度上測量的資料。若假設不能被驗證,則應採用無母數方法。在序位尺度上測量的變數,如焦慮評分量表,應該使用無母數方法進行分析,因為不能做出常態性分佈之假設。因此,無母數檢定可用於分析連續或序位尺度上測量的資料(c正確)。
有時,會使用母數法分析在數值中可能存在較大分散範圍的序位尺度測量之變數,但這種檢定可能是沒有意義的。假設檢定將為基於樣本估計值推論到母群體的參數。然而,序位尺度由具有自然順序的範疇組成,因此測量本身是間斷的而非連續的;刻度點間的差異幾乎沒有實質意義或價值。
無母數法可以在所有情況下使用,無論是否可以對所分析的變數作出母群體常態分佈的假設。然而,不建議這樣做。如果母數檢定的所有假設都被滿足,則母數法相較無母數法更具優勢,因為若在母群體中存在結果差異,母數法將具有更大的統計檢定來偵測治療組間的結果差異(d正確)。統計檢力在之前問題中已經描述過了[6]。此外,無母數法是有限的,因為它們主要是導致顯著性二分決策的檢定;與母數法不同,它們通常不允許基於樣本估計值對母群體參數的信賴區間進行陳述。
[Showme說明:母數分析法除了由P值判定有無顯著差異外,還能估算母群體差異的信賴區間,但無母數分析僅能檢定由無顯著差異,但無法估計母群體差異的信賴區間。]
採用獨立樣本t test 和Mann-Whitney U test對兩個獨立組別進行比較。當有三個及以上的獨立組別時,母數和無母數法分別是變異數分析(ANOVA)和Kruskal-Wallis test [7,8]。
Reference:
[1] Porto AMF, Coutinho IC, Correia JB, et al. Effectiveness of antenatal corticosteroids in reducing respiratory disorders in late preterm infants: randomised clinical trial. BMJ 2011;342:d1696.
[2] Sedgwick P. Understanding statistical hypothesis testing. BMJ 2014;348:g3557.
[3] Sedgwick P. Independent samples t test. BMJ 2010;340:c2673.
[4] Sedgwick P. The Normal distribution. BMJ 2010;341:c6085.
[5] Sedgwick P. Log transformation of data. BMJ 2012;345:e6727.
[6] Sedgwick P. The importance of statistical power. BMJ 2013;347:f6282.
[7] Sedgwick P. One way analysis of variance. BMJ 2012;344:e2427.
[8] Sedgwick P. Non-parametric statistical tests for independent groups: numerical data. BMJ 2012;344:e3354.
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
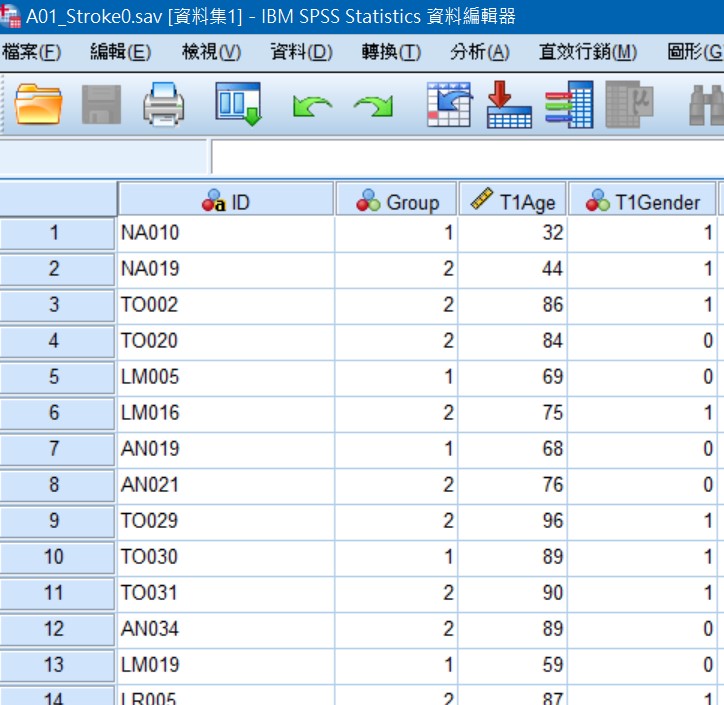
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖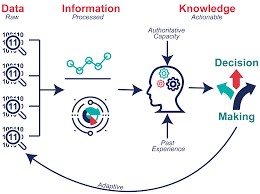
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


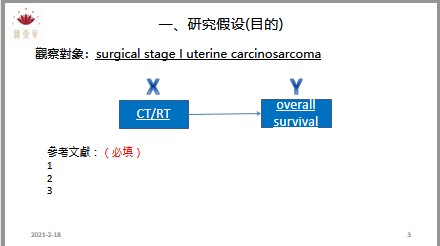
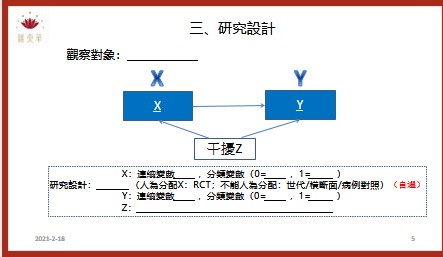
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。