
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
BMJ小小統計問題(62)特輯:
Analysis of matched case-control studies (配對病例對照研究之分析)—(上)
前言:
講述概念的課程跟文章吃力不討好,而實作課程跟文章比較受歡迎。概念跟理論論述型的,很燒腦。雖然不甚討喜,不過個人一向喜歡,知其然更知其所以然,建立mental map個人是比較喜歡的。這期內容跟下期內容都是整理自同一篇文獻,不簡單喔!會繞暈頭!真的想看再看。
上期的61題跟之前文章才提過,配對是在研究設計階段控制干擾因素的常用方法,但這期怎麼就來打臉了呢?個人覺得,要了解一個現象,就要看正、反兩派的觀點,看的角度不同,邏輯原理不同,所得結論也不相同。這樣才能了解我們為何而用,而不是一昧的me too。用的是否正確,也不清楚,這是很危險的。
這篇文章開宗明義提出病例對照研究常見的兩個誤區,拍拍拍,臉打得有點痛。不過稍安勿躁,好好讀完,所獲甚多。
最近讓新同事嘗試新的業務跟活動,沒試過就試試吧。實踐出真知,個人是信的。公司於10/22(六)舉辦”A03配對研究設計與分析”的實體課程,10/24(一)該線上課程會於匯東華統計學院上架。考量疫情之故,所以特別規劃線上課程。有興趣的朋友可以參考。
本文開始~
關於病例對照研究有兩個常見的誤解:
1.配對本身消除(對照)因配對因素而產生的干擾。
2.如果進行了配對,需要進行“配對分析”。
然而,病例對照研究中的配對並不會控制配對因子的干擾;實際上,即使在原來母群體中不存在,配對因子也會導致干擾。因此,配對設計可能需要在分析時控制配對因子。
然而,配對設計並不需要採用配對分析。只要沒有稀疏資料(Sparse data)的問題,使用“標準”(非條件,unconditional)分析就可以獲得針對配對因子的控制,而不損失效度,並可能提高精確度,而“配對”(條件,conditional)分析可能是不需要或不適合的。
(Showme提醒:Sparse data是指很多筆資料缺乏數據)
|
總結: 1.病例對照研究中的配對不會控制配對因子的干擾。 2.配對設計可能需要在分析時控制匹配因子。 3.配對設計並不需要使用配對的分析法。
“標準的”(非條件的)分析可能是最有效和最合適的,而“配對的”(條件的)分析可能不需要或不合適的。
|
病例對照研究中通常會使用如年齡或性別等因素進行配對[1]。目的在便於改善在透過改善精確度(precision)下而改進研究效率(efficiency) (在某些條件下)。研究精確度的改善可由在執行分析時,控制配對因素(如年齡、性別)或在分析時控制無法量化的因素(如要控制居住地特質,我們可以選擇鄰居作為對照組)。
(Showme說明:Precision is the degree of closeness of the measurements with each others = repeatability and producibility error = 測量結果一致性,即信度)
效率的提高是因為這種作法能確保在不同的干擾分層中具有相同數量的病例和對照組人數。例如,在一項肺癌的研究中,如果從來源母群體中隨機抽樣對照組,其年齡分佈將比肺癌病例的年齡分佈年輕許多。因此,當在分析中控制年齡時,年輕層可能以對照為主,病例較少,而老年層可能以病例為主,對照較少。因此,如果對照組能與病例組進行年齡配對,以確保每個年齡層的病例和對照數量大致相等,則可能提高統計精準度(statistical precision)。
關於病例對照研究有兩個常見的誤解:
- 1.配對本身消除配對因素造成的干擾。
- 2.若有執行配對設計,則需要進行”配對分析”。
配對研究設計不會控制由被配對的因素所引起的干擾。事實上,即使它在來源母群體中不存在,透過配對可能會導致配對因素造成干擾[1]。原因很複雜,這裡只作簡單的討論。
從本質上說,配對過程使控制組不僅在配對因數方面,且在暴露本身方面也更近似於病例組。這將致使一個需在分析中加以控制的偏差。例如,假設我們正在進行一項關於貧窮和死亡(全死因)的病例對照研究,我們選擇兄弟姐妹作為對照(亦即,對於每個死亡個案,選擇同住且仍然在世的兄弟姐妹作為對照來配對居住地與家庭的影響)。
在此情形下,會傾向於為每一個死亡的弱勢群體選擇一個弱勢對照,為每一個死亡的富裕個案選擇一個富裕對照。我們會發現,在病例組和對照組中,弱勢族群的比例大致相同,然後會發現貧窮和死亡率之間幾乎沒有關聯。配對引入一個偏差,不過可以通過在分析時控制所配對的因數來加以控制。
因此,配對設計(幾乎總是)需要在分析中控制配對因素。然而,此並非意味著需要使用配對的分析法進行分析,使用更簡單的方法來控制配對因素即已足夠。雖然此點已被近期研究所認知[2-5],不過其他研究[6-9]並無討論本議題並且呈現配對分析是使用配對病例對照研究設計時的唯一選擇。實際上,標準分析不只是有效的且在實務上也更容易被執行,並且其統計精確度亦較佳。
本文作者將探討與說明使用配對病例對照研究的問題。
分析病例對照研究的選擇
非配對的病例對照研究通常使用Mantel-Haenszel method [10]或unconditional logistic regression [4]進行分析。前者涉及熟悉的方法,即為干擾因素的每一分層生成2×2 (暴露-疾病)層 (如,若有5個年齡組和2個性別組,則將有10個2×2表格,每個表顯示某一特定分層中暴露與疾病間的關聯),然後生成各分層的匯總(平均)效果量。
Mantel-Haenszel估計是穩健的(robust),不受特定分層中樣本數較少的影響(前提是病例或對照在暴露或非暴露情況的總數是足夠的),儘管若某些層涉及的樣本較少(例如,只有一個病例和一個對照),則可能很難或不可能控制配對因素以外的因素。此外,Mantel-Haenszel方法在只有少數干擾分層的情況下適合,但若需要調整的干擾分層太多,則會遇到樣本數較少的問題(如,只有病例而無對照組)。若有此情況,logistic regression可能是首選,因為它使用最大概似法(maximum likelihood methods),能夠調整更多的干擾因素。
假設我們為每個病例選擇一個在相同五歲年齡組的對照(即若病例年齡為47歲,則選擇了一個年齡為45-49歲的對照)。然後,可以進行標準分析,將所有病例和對照組以5歲年齡作分組並使用unconditional logistic regression [4](或Mantel-Haenszel method [10])來調整配對因素(年齡組);若有8個年齡組,則該分析將有8個分層(由7個年齡組虛擬變數來表示),每個分層都有多名病例和對照。或者,我們可以使用conditional logistic regression (或對應於Mantel-Haenszel method之配對方法)進行配對分析(即,為每個病例保留一個對照配對);若有100個病例對照對,則該分析將有100個分層。
使用conditional logistic regression (而非unconditional logistic regression)的主要原因為,當分析的分層個案數非常小時(例如,每個分層只有一個病例和一個對照),使用unconditional methods會出現資料稀疏的問題[11]。例如,即使只有200個研究參與者,但若有100個分層,同樣需要99個虛擬變數來表示它們。在這種極端情況下,unconditional logistic regression會有偏差,所產生的OR估計值會是conditional logistic regression 產生的OR估計值之平方[5, 12]。
以年齡作為配對因素的範例。
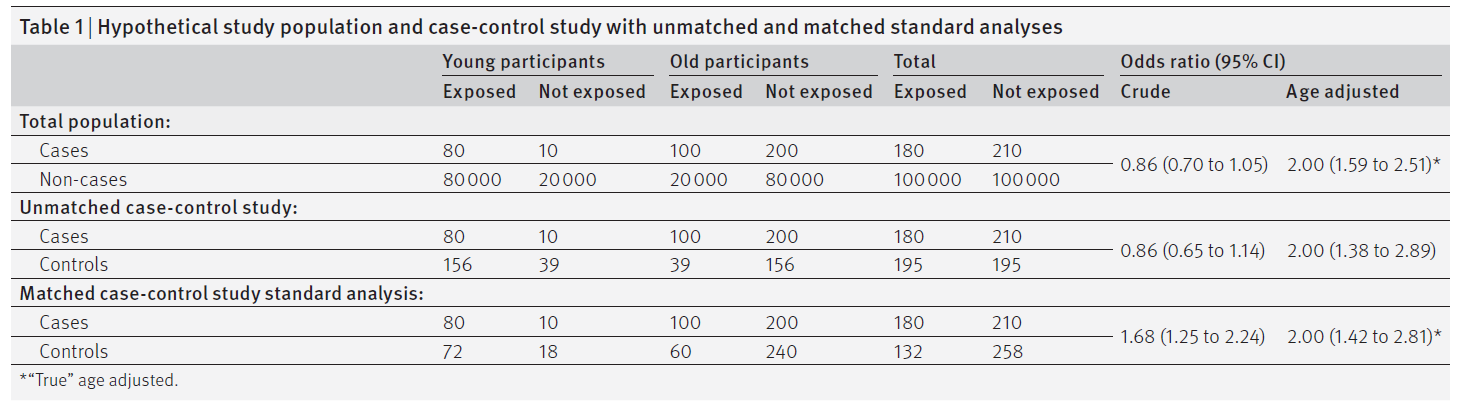
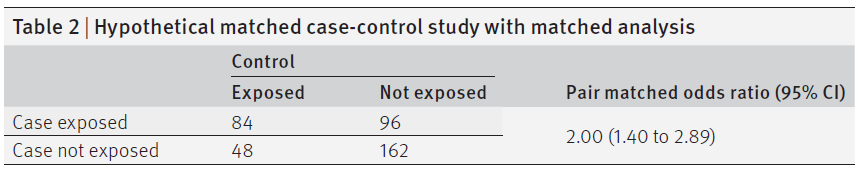
表1給為一個以族群為基礎(population-based)的病例對照研究中年齡配對的例子,並顯示母群體的“真實”結果、非匹配病例對照結果,及使用標準分析的年齡配對病例對照研究的結果。表2顯示使用配對分析的同齡配對病例對照研究的結果。所有的分析都是使用Mantel-Haenszel method執行,但這與相應的(unconditional or conditional) logistic regression分析結果相似。
Source: Pearce, Neil. "Analysis of matched case-control studies." BMJ 352 (2016).
Source: Pearce, Neil. "Analysis of matched case-control studies." BMJ 352 (2016).
表1顯示,母群體中粗OR為0.86 (0.70 - 1.05),但當分析調整年齡(使用Mantel-Haenszel Method)時,OR變為2.00 (1.59 - 2.51)。顯示年齡有明顯的干擾作用——病例大多為老年人,老年人的暴露情況低於年輕人。總體而言,有390個病例,當從母群體(一半暴露和一半未暴露)中的非病例人群中隨機選擇390個對照時,得到相同的粗的(0.86)和調整後(2.00)的OR,但其具有更寬的信賴區間,反映出病例對照研究中較少的對照人數。
下期預告:
為何配對因素需要在分析時被控制
配對研究不需要使用配對分析法
標準分析法的優點
結論
#BMJ
#醫學統計
#Matching
#case-control study
#Mantel-Haenszel Method
#conditional logistic regression
#unconditional logistic regression
Reference:
1. Rothman KJ, Greenland S, Lash TL, eds Design strategies to improve study accuracy. Modern epidemiology.3rd ed. Lippincott Williams & Wilkins, 2008.
2. Rothman KJ. Epidemiology: an introduction. Oxford University Press, 2012.
3. Rothman KJ, Greenland S, Lash TL, eds. Modern epidemiology.3rd ed. Lippincott Williams & Wilkins, 2008.
4. Breslow NE, Day NE. Statistical methods in cancer research. Vol I: the analysis of case-control studies.IARC, 1980.
5. Kleinbaum DG, Kupper LL, Morgenstern H. Epidemiologic research: principles and quantitative methods.Lifetime Learning Publications, 1982.
6. Dos Santos Silva I. Cancer epidemiology: principles and methods.IARC, 1999.
7. Keogh RH, Cox DR. Case-control studies.Cambridge University Press, 2014doi:10.1017/CBO9781139094757
8. Lilienfeld DE, Stolley PD. Foundations of epidemiology.3rd ed. Oxford University Press, 1994.
9. MacMahon B, Trichopolous D. Epidemiology: principles and methods.2nd ed. Little Brown, 1996.
10. Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J Natl Cancer Inst 1959;22:719-48.
11. Robins J, Greenland S, Breslow NE. A general estimator for the variance of the Mantel-Haenszel odds ratio. Am J Epidemiol 1986;124:719-23.
12. Pike MC, Hill AP, Smith PG. Bias and efficiency in logistic analyses of stratified case-control studies. Int J Epidemiol 1980;9:89-95. doi:10.1093/ije/9.1.89.
13. Brookmeyer R, Liang KY, Linet M. Matched case-control designs and overmatched analyses. Am J Epidemiol 1986;124:693-701.
14. Greenland S. Applications of stratified analysis methods. In: Rothman KJ, Greenland S, Lash TL, eds. Modern epidemiology.3rd ed. Lippincott Williams & Wilkins, 2008.
15. Vandenbroucke JP, Koster T, Briët E, Reitsma PH, Bertina RM, Rosendaal FR. Increased risk of venous thrombosis in oral-contraceptive users who are carriers of factor V Leiden mutation. Lancet 1994;344:1453-7. doi:10.1016/S0140-6736(94)90286-0.
16. Cardis E, Richardson L, Deltour I, et al. The INTERPHONE study: design, epidemiological methods, and description of the study population. Eur J Epidemiol 2007;22:647-64. doi:10.1007/s10654-007-9152-z.
17. Mansournia MA, Hernán MA, Greenland S. Matched designs and causal diagrams. Int J Epidemiol 2013;42:860-9. doi:10.1093/ije/dyt083.
18. Hernán MA, Hernández-Díaz S, Robins JM. A structural approach to selection bias. Epidemiology 2004;15:615-25. doi:10.1097/01.ede.0000135174.63482.43.
Source: BMJ 2016; 352 doi: https://doi.org/10.1136/bmj.i969
Cite this as: BMJ 2016;352:i969
Reference: Pearce, Neil. "Analysis of matched case-control studies." BMJ 352 (2016).
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
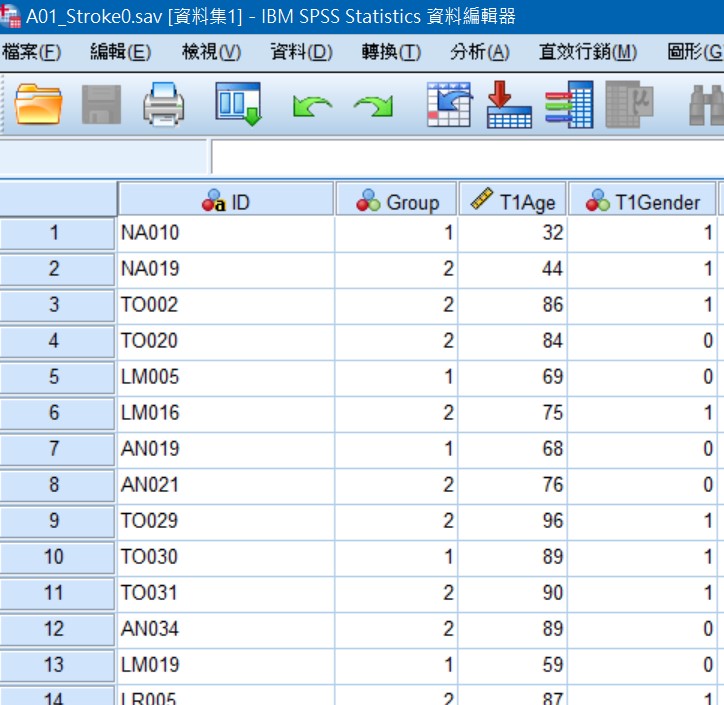
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖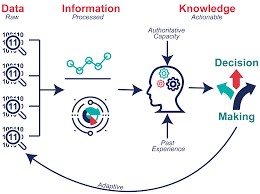
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。