
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
BMJ小小統計問題(78):
Sample size: how many participants are needed in a trial?
(樣本量:試驗需要多少參加者?)
前言:
統合分析相關主題已經談完,開始回到常用統計的主題。本周主題為計算試驗所需的樣本數。本例為採用優勢試驗 (superiority trial),及組間平均值差異在臨床感興趣最小效果之上,此為第一項學習重點;第二項學習重點在於樣本數計算需考慮的指標;第三項學習重點在於檢定力(POWER)的解釋,本篇內容解釋得很清楚;第四項重點在對於結果的推論。很容易就踩坑,需要特別注意。Hope u enjoy it
Cite this as: BMJ 2013;346:f1041
https://www.bmj.com/content/346/bmj.f1041
題目
研究人員調查基於家庭的早期介入對2歲兒童身體質量指數(BMI)之效果。採用隨機對照優勢試驗 (superiority trial)。介入措施在出生後24個月內,除了社區衛生護士之常規性兒童照護服務外,還包括8次家訪。對照組僅接受常規的兒童護理服務。參與者都是初為人母的母親和她們的嬰兒。主要結果是兒童在2歲時的BMI [1]。
樣本數計算基於2歲時治療組間平均BMI差異為0.25單位,採雙尾檢定,顯著水準設為0.05,檢定力為80%。假設各組觀察值的標準差相同,均為1.5 BMI單位。總樣本數為504名參與者(每治療組252名)。考慮約20%的退出率,需要招募630名初為人母之參加者。總共667位母親及她們的嬰兒被招募到本項試驗。
2歲時,介入組之平均BMI顯著低於對照組(16.53 v 16.82;差異值0.29,95%信賴區間 −0.55 至 −0.02;P = 0.04)。研究人員得出結論,由訓練有素的社區護士提供的基於家庭的早期介入對降低2歲兒童的平均BMI是有效的。
下列敘述何者正確?(複選)
a)治療間的平均BMI差異為0.25是臨床感興趣的最小效果
b)如果檢定力提升至90%,所需的樣本數將增加
c) 型I錯誤(type I error)固定為5%,用於主要結局的統計檢定
d)增加樣本數會降低型I錯誤(type I error)
e)可以得出結論,在母群體中,組別間的平均BMI至少存在0.25的差異
答案
a,b,c,d正確,e錯誤
詳細說明
這項優勢試驗 (superiority trial)目的在於確定基於家庭的早期介入效果是否優於對照治療,或反之。優勢試驗已經說明過[2]。雖然預測,與對照治療相比,基於家庭的早期介入能夠降低2歲時的平均BMI,但有時結果會出乎意料,重要的是,統計假設檢定允許對照治療較佳的可能性。因此,在BMI的結局測量中,採用傳統的統計學假設檢定中的雙尾檢定來比較治療組[3]。若治療組間的平均BMI差異至少為0.25個單位,則其中一種治療被認為比另一種治療更有效。這種差異被稱為臨床感興趣之最小效果(a正確),代表了一種治療在臨床上被認為比另一種治療更有效所需的平均BMI的最小差異。更大的差異顯然也表明優勢——亦即,治療組間存在顯著差異。然而,若組間差異較小,則計算的樣本數無法證明處理組間的顯著差異。最小的臨床效果由研究人員根據臨床經驗或以往的研究提出的。
試驗中觀察到的治療組間BMI的差異估計母群體效果,換句話說,若將結果應用於初為人母個案及嬰兒的母群體中,治療組間將會看到的差異。最小臨床效量可能在母群體中不存在,但若存在,需要最大化它在試驗中被偵測到的機率。為了使這一機率最大化,需要一個最佳樣本數。為了計算樣本數,除了指定臨床感興趣的最小效果外,研究人員還需要指定所需的檢定力和臨界顯著性水準;他們還需要提供每個治療組BMI預期標準差。基於以前的研究,BMI的標準差假設在每組中相等。
為了確定觀察到的平均BMI差異是否顯著,進行統計假設檢定並推導出P值。假設檢定是基於無限次抽樣的假設情況。對於上面的例子,在相同條件下,無限個樣本中的每一個有相同大小的樣本數。檢定力即為在母群體存在臨床感興趣最小效果的情況下,在這些重複樣本被偵測出來之百分比(在本例中設為80%)。
在計算樣本數時,通常建議將檢定力設置為80%以上。檢定力通常固定在80%或90%。在樣本數計算中,增加檢定力會增加所需的樣本數(b正確)。因為隨著樣本數的增加並接近母群體數,試驗中觀察到的BMI差異將與母群體中相近。因此,隨著樣本數的增加,檢定力也會增加,因為若臨床感興趣的最小效果存在於母群體中,則它更有可能在試驗中被看到。
為了比較介入組和對照組,提出具有0.05臨界顯著性水準的雙尾假設檢定。在統計假設檢定中,顯著性的臨界水準通常設為0.05。顯然,在試驗開始前,不知道母群體中治療間的平均BMI是否存在差異。若不存在差異,則重要的是將犯型I錯誤(type I error)的機率降至最低。如果在母群體中治療之間的平均BMI沒有差異的情況下,拒絕虛無假設而選擇對力假設,將會出現型I錯誤。提前設置臨界顯著性水準確保發生型I錯誤最大機率為0.05 (5%)(c正確)。
如上所述,假設檢定是基於無限次抽樣的假設情況。由於臨界顯著性水準被設為0.05,因此對於這無限數量樣本中的5%,虛無假設將被拒絕,而選擇對立假設。因此,對於任何假設檢定,拒絕虛無假設的最大機率為0.05。因為任何假設檢定都可能導致型I錯誤,I型錯誤的最大機率為0.05 (c正確)。型I錯誤的機率受樣本數影響。隨著樣本數的增加並接近母群體數,試驗中平均BMI的差異將與母群體中相似,從而降低了發生型I錯誤的可能性(d正確)。
雖然研究發現兩種治療方法在2歲時的平均BMI有顯著差異,但不能得出結論,在母群體中,不同治療方法間肯定存在至少0.25單位的平均BMI差異(臨床感興趣的最小效果)(e錯誤)。試驗提供足夠的證據來拒絕虛無假設,支援對立假設,結論是不同治療之間存在差異。然而,這個結果有可能是型I錯誤,儘管如上所述,這種機率最多為0.05(5%)。
研究人員必須計算最佳樣本數。若樣本數太小,可能無法代表整個母群體,會導致試驗缺乏說服力。太大的樣本可能耗時、昂貴,且是不道德的。所需要的樣本數調整為估計20%的退出率。參與者因各種原因離開試驗並不罕見,因此必須調整樣本數以考慮到這一點。退出的程度可從以前的試驗中估計出來。
Reference
[1] Wen LM, Baur LA, Simpson JM, Rissel C, Wardle K, Flood VM. Effectiveness of home
based early intervention on children’s BMI at age 2: randomised controlled trial. BMJ
2012;344:e3732.
[2] Sedgwick P. Superiority trials. BMJ 2011;342:d2981.
[3] Sedgwick P. Statistical hypothesis testing. BMJ 2010;340:c2059.
#BMJ
#醫學統計
#Sample size
#Superiority trial
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖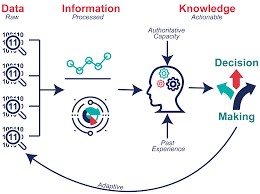
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


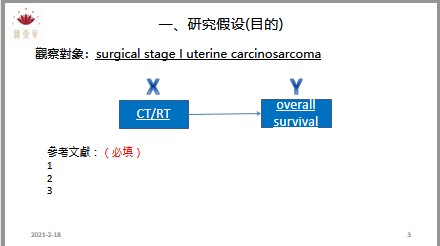
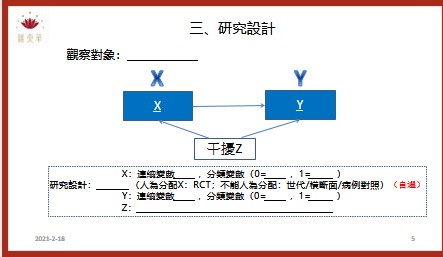
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。