
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
BMJ小小統計問題(165):Bias in observational study designs: prospective cohort studies(觀察性研究設計之偏差:前瞻性世代研究)
前言
本期文章探討 #前瞻性世代研究(prospective cohort study)中的常見偏差,尤其是 #選擇偏差、 #脫落偏差及 #回應偏差等問題,並說明在設計研究時辨識與控制這些偏差的重要性。準確處理這些偏差有助於提升研究結果的信度與應用性。推薦一讀。
另本人拙作”ChatGPT於系統性文獻回顧和統合分析之應用”於#台灣護理學會 發行之護理雜誌 2024年10月71卷 5期刊登,歡迎大家批評指教。往後會陸續發表本系列內容,也請大家持續關注。Hope u enjoy it!
我們的目標:在AI時代來臨,能夠善用AI工具,擺脫耗時費力的瑣事,專注於更有價值的事務上,持續進化!
-
會員專屬權益: https://pse.is/65bzhq
更多學習資源:
聯繫我們的官方LINE:@medatatw,感謝您一路相伴,讓我們在AI時代一起進化! ✨
問題:
女性健康倡議觀察研究(Women's Health Initiative Observational Study)是一項前瞻性世代研究(prospective cohort study),旨在調查停經後女性之發病率和死亡率的原因。該研究於1993年至1998年期間,於美國的40個臨床中心招募93,676名年齡介於50到79歲間的女性。排除那些預計存活少於三年或患有諸如酒精中毒、藥物依賴或癡呆等複雜疾病的女性。研究者使用這些數據來探討吸菸與侵襲性乳腺癌風險間之關係。針對本項分析,從原始世代中排除13,686名女性,包括12,075名在基線時有癌症病史(非黑色素瘤皮膚癌除外)之女性,及1,168名吸菸狀態遺漏的女性。此外,另有443名女性在追蹤過程中失去追蹤。最終納入分析的樣本數為79,990名女性[1]。
主要結果是病理學診斷的侵襲性乳腺癌。吸菸行為在基線時通過自報的終生被動和主動吸菸暴露資料進行評估。於基線還收集其他可能的干擾因素,包括年齡、種族、身體質量指數(BMI)、體力活動和酒精攝入。這些女性被前瞻性追蹤至2009年8月14日,或者她們被診斷為侵襲性乳腺癌,取兩者中的較早者。平均追蹤時間為10.3年。總共確定3520例侵襲性乳腺癌病例。與從未吸菸女性相比,有吸菸史者的乳腺癌風險(hazard ratio, HR)顯著增加(adjusted hazard ratio 為1.09,95%信賴區間1.02-1.17),現吸菸者的HR也顯著增加(1.16,95%置信區間1.00至1.34)。在從未吸菸的女性中,暴露於最廣泛被動吸菸的女性與從未暴露於被動吸菸的女性相比,其乳腺癌HR顯著增加(1.32,95%賴信區間1.04-1.67)。研究者得出結論,主動吸菸與停經後女性乳腺癌風險增加相關,且被動吸菸也可能增加乳腺癌風險。
下列哪些偏差可能影響上述世代研究結果?
a) 分配偏倚(allocation bias)
b) 脫落偏倚(attrition bias)
c) 干擾因素(confounding)
d) 健康入組效應(healthy entrant effect)
e) 回應偏差(response bias)
f) 選擇偏差(selection bias)
答案:
b、c、d、e和f均正確,a錯誤。
詳細說明:
此為一項前瞻性世代研究,旨在調查吸菸行為與停經後女性侵襲性乳腺癌間的關係。前瞻性世代研究設計本質上屬於觀察性設計[2],容易受到各種偏差(bias)的影響。偏差為一種系統性誤差(systematic error),與隨機變異或精度不足不同,可能出現在招募參與者、測量風險因素和結果、或者報告結果的過程中。觀察性研究通常會面臨三種主要的偏差:選擇偏差、訊息偏差與干擾因素。以下是這些類型的具體解釋。
選擇偏差
選擇偏差是一個常見的問題,指樣本不能充分代表母群體之系統性誤差。在本研究中,樣本來自40個臨床中心,儘管這樣可以涵蓋較廣泛的地理範圍,但仍有可能無法完全代表美國所有停經後女性,導致外部效度下降。此外,無回應偏差也可能發生,因為願意參加研究和不願意參加的女性之間可能存在無法量化的差異,影響結果的廣泛應用性(外部效度,概化能力)。
脫落偏差(b正確)可能發生在追蹤期間參與者失聯的情況下,尤其是當失聯的原因與風險因素(如吸菸)或結果(如乳腺癌的診斷)相關時。在這項研究中,有443名女性在追蹤過程中失聯,雖然比例較低,但仍可能導致系統性誤差。若失聯者的行為或風險特徵與完成追蹤者不同,將會影響結果的內部效度,特別是低估吸菸的危險性。
回應偏差(e正確)屬於訊息偏差的一種,可能出現在參與者自報行為時的不準確性。比如女性可能會低估她們的吸菸習慣,因為她們知道吸菸對健康有害,此會導致結果的不準確。此偏差會導致研究結果中的吸菸率低於實際情況,進而影響乳腺癌風險與吸菸行為的關聯評估。
干擾因素(c正確)本這項研究中可能存在。干擾因素可能會混淆吸菸與乳腺癌之間的真實關係。雖然研究者在基線時收集潛在干擾因素(如酒精攝入),並在分析中進行調整,但不太可能捕捉到所有潛在的干擾因素。酒精攝入與吸菸行為間的密切關係,顯示它可能為一個干擾因素,必須在分析中進行調整,以避免錯誤的結論。
健康入組效應(d正確)指的是,由於研究招募的女性在基線時健康狀況良好,因此在研究初期,這些女性的疾病發生率和死亡率可能會低於一般人群。然而,隨著時間的推移,這些指標會逐漸回到一般人群的水準。此種效應需在結果分析時加以考慮,否則可能會低估研究開始階段的風險。
分配偏差(a錯誤)通常發生在隨機對照試驗中,當參與者被分配到不同治療組時可能出現。在觀察性研究中,參與者並非隨機分配到不同的處置組,因此不會出現分配偏差的問題[3]。
Reference:
[1] Luo J, Margolis KL, Wactawski-Wende J, Horn K, Messina C, Stefanick ML, et al.
Association of active and passive smoking with risk of breast cancer among postmenopausal women: a prospective cohort study. BMJ 2011;342:d1016.
[2] Sedgwick P. Prospective cohort studies: advantages and disadvantages. BMJ 2013;347:f6726.
[3] Sedgwick P. Why randomise in clinical trials? BMJ 2012;345:e5584.
- #匯東華 #BMJ統計問題 #醫學統計 #前瞻性世代研究 #選擇偏差 #觀察性研究 #醫學研究方法 #生物統計
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
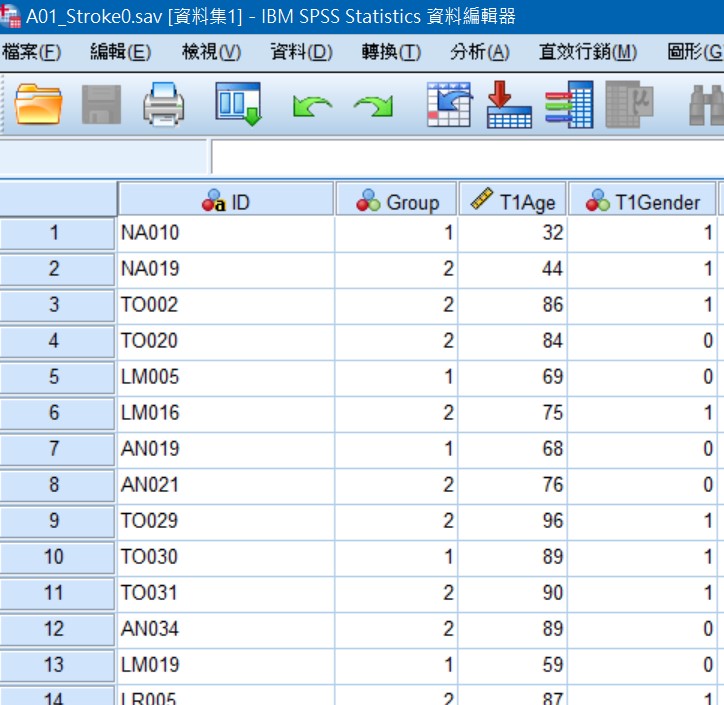
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖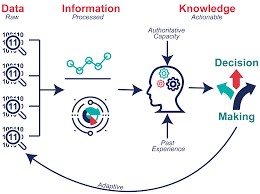
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


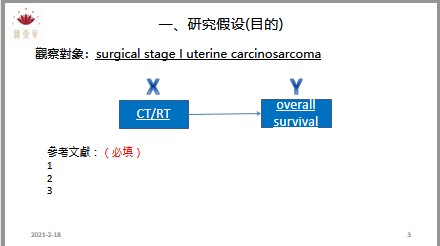
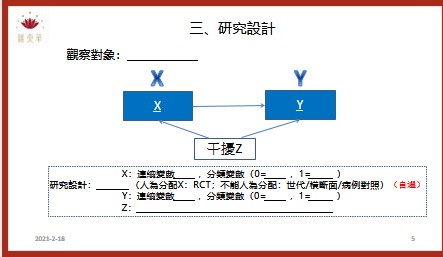
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。