
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
❓Q & A:多重共線性 Multicollinearity

有幾位同學詢問到關於多重共線性問題,透過本篇文章進行說明。構建多重線性迴歸模型時,要求各個預測變數間互相獨立,不存在多重共線性。所謂多重共線性,發生在預測變數彼此間高度相關時,其中某個預測變數能被其他預測變數組成的線性組合來解釋。
醫學研究中常見的生理資料,如年齡、BMI、收縮壓、舒張壓、血脂、總膽固醇和三酸甘油脂等等,這些變數間本身由於生理機制之故,彼此間原本就存在一定關聯。若在建構迴歸模型時,把這些具有多重共線性之變數同時置於模型中,可能出現方程式所估計出來的偏迴歸係數明顯背離常識,甚至出現方向相反,導致迴歸模型不穩定與精確度降低。
舉一例說明:假設某位研究者正在研究患者的心血管疾病風險(outcome variable)與年齡、血壓、體重、總膽固醇(predictor variables)的關係。
步驟1 偵測多重共線性:
首先確認這些預測變數間之相關性。結果發現這些變數間存在高度的相關。例如,年齡可能與血壓高度相關,因為年齡越高,血壓可能越高。計算變異膨脹因子((Variance Inflation Factor,VIF)> 5,存在多重共線性。
步驟2 處理多重共線性:
2.1 變數選擇:可選擇保留與結果變數最相關的預測變數,並移除其它相關的預測變數。如,若年齡與結果變數的相關最強,則保留年齡,並移除其它預測變數。可以透過向前選擇(first add the variable that has the greatest correlation with the outcome)、向後選擇(first remove the variable that has the least correlation with the outcome),或逐步選擇(a combination of forward and backward)完成。
(1)向前選擇(Forward Selection):開始時不包含任何變數,為空模型,之後逐步加入對目標變數影響最大的變數。在每一步中,考慮加入的是在所有剩餘預測變數中能最大提升模型配適度的變數。(空à逐步選入與預測變數最相關之變數,直到所餘變數皆無顯著提升模型配適度à停止)
(2)向後選擇(Backward Selection):開始時包含所有變數,即全模型,之後逐步排除對目標變數影響最小的變數。在每一步中,考慮刪除的是在當前模型中能最小降低模型適合度的變數。(全滿à刪除對目標變數影響最小的變數,直到所餘變數皆無法刪除為止à停止)
(3)逐步選擇(Stepwise Selection):逐步選擇法是向前選擇和向後選擇之結合。首先從空模型開始,選擇能最大提升模型適合度的變數加入模型,然後考慮刪除在當前模型中能最小降低模型配適度的變數,反覆進行,直到模型配適度無法進一步提升。(向前à向後)
[備註:建構預測模型,另一種變數選擇策略為Akaike Information Criterion (AIC) 和 Bayesian Information Criterion (BIC),在特定情況下是一種更好的變數選擇策略。AIC和BIC的計算方法考慮模型的 goodness-of-fit(數據與模型的匹配度)和模型的複雜度(通常與模型中的預測變量數量有關)。在選擇模型時,通常選擇 AIC 或 BIC 值最小的模型。]
2.2.降維:可以通過主成分分析(Principal Component Analysis,PCA)將多個高度相關的變數轉化為一組新的、彼此無關的變數。這些新的變數(即主成分)可以保留原來變數的大部分訊息,同時消除多重共線性。
2.3.增加樣本數:可以嘗試收集更多的樣本。有時候,多重共線性的問題可能源於樣本數不足。
6-7月份公司課程招生中,精彩可期。
✅7/1(六)AI01-探索ChatGPT、以及AI02-活用ChatGPT
“AI01課程將帶你了解ChatGPT的基本原理,並學習如何在日常工作或研究中運用它。AI02課程則是進階課程,將帶你深入瞭解如何在研究中活用ChatGPT,包括概念生成、文獻整理,到論文撰寫與審稿回覆等六大場景,及對學術研究的影響。”
✅6/17(六)「WS1-統合分析研究工作坊:基礎班」、6/18(日)「WS2-統合分析研究工作坊:實戰班」招生中!
“帶你從零基礎開始,由淺入深進入系統性綜述/統合分析的世界。有理論,更有實務。”
✅7/8(六)「WS4-SPSS進階醫學統計:縱貫性研究設計與分析--重複測量分析法」招生中!
#多重共線性 #複迴歸 #向前淘汰法 #向後淘汰法 #逐步淘汰法
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。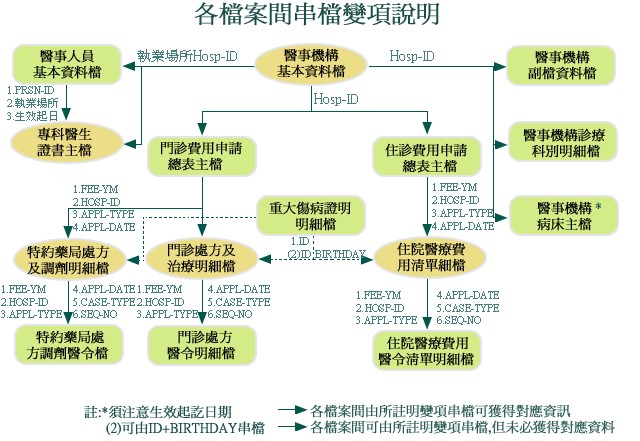
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖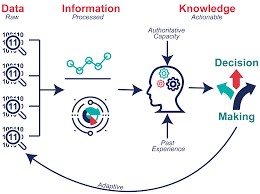
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


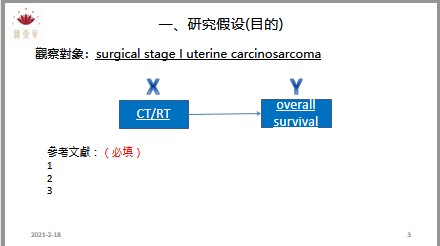
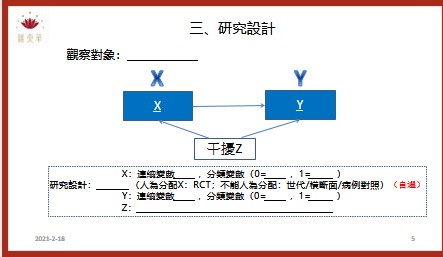
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。