
![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~
![]()
the Lancet:醫學研究統計:精準報告的專業建議
Recommendations for accurate reporting in medical research statistics
前言
不知道怎麼報告統計分析結果才不會顯得外行嗎?才不會踏到雷區嗎?2024年2月17日,知名醫學期刊《Lancet》刊登了一篇通信文章(Correspondence)。該文依據過去三年間提交至《Lancet》的逾千篇稿件進行的評審結果,彙總一些統計學上常見的錯誤。同時,文章還針對如何有效避免這些錯誤提出了具體指導建議。本短片為這些建議的總結。若想針對醫學統計學核心概念進行系統性理解,強力推薦新上市課程【eB02-小白的醫學統計必修課(上)】,專治統計不全症。
-----
路徑:匯東華官網/學習專區/BMJ小小統計問題
-
2024年三~四月課程課程介紹與報名
- ✅線上課程 :白話效果量(effect size):概念、分析與應用✅
- ✅[線上課程]:3/29(五)小白的醫學統計必修課(下)
- ✅3/16 (六)[額滿]-實體課程:ChatGPT於科學研究之應用
- ✅3/17 (日)[額滿]-實體課程:AI02-ChatGPT高效醫學論文寫作
- ✅4/13 (六)[確定開班]-實體課程:A01-SPSS實戰課程:零基礎入門統計課程 [確定開班]
- ✅4/14 (日)[確定開班]-實體課程:A05-SPSS統計實戰班:問卷與量表統計分析
- ✅[實體]4/13(六)A01-SPSS實戰課程:零基礎入門統計課程 [確定開班] ☑️
- ✅[實體]4/14(日)A05-SPSS統計實戰班:問卷與量表統計分析 [確定開班] ☑️
-----
✨本公司提供【流行病學】與【生物統計學】線上課程,請至匯東華統計學院
-----
Recommendations for accurate reporting in medical research statistics
醫學研究統計:精準報告的專業建議
整理者:陳秀敏
整理日期:2024年3月22日
總結:準確報告統計資料的基本建議
-
描述定量資料分布:應用算術平均數和標準差(SD)或中位數和四分位距(IQR)來描述定量資料的分布特性。在補充材料中,應提供資料的直方圖或詳細表格以供參考。
-
一圖抵萬言:檢查所有模型假設,盡可能使用圖形呈現。
-
精確報告P值:不宜僅以P值小於或大於05(或0.01)來報告結果,而應提供精確的P值。例如,若P值為0.032,則應記述為P=0.032而非P<0.05。對於極小的P值,可以記述為P<0.0001。
-
結果描述準確性:除非區間估計值內的所有效果在臨床上都不重要,否則不要將結果報告為「無效果」。
-
基於臨床重要性解釋結果:分析結果應基於臨床重要性進行解釋,適當估計與 95% Cls 的關係,而非僅根據統計顯著性。
-
識別干擾因子:根據背景資訊(如因果有向無環圖,causal directed acyclic graphs,DAGs)而非顯著性檢定來確定潛在的干擾因子。
-
處理遺漏值:高比例的遺漏值可能影響研究結果的可靠性。不應簡單刪除遺漏值,而應考慮使用逆概率加權、多重插補等方法來處理。。
-
稀疏資料偏差(sparse-data bias)處理:對於比率估計中的稀疏數據(sparse-data),應使用專門的方法來評估和處理相關的數據偏差。
-
高發生率結局的報告方法:若研究結局事件的發生率較高,則應報告相對危險性(risk ratio, RR)或風險差值(risk difference, RD),而非僅報告勝算比(odds ratio, OR)。
-
評估交互作用:即使在分析中採用累乘模型,也應評估累加交互作用的可能性及影響。
一、針對描述性統計:
1.定量資料:通常使用mean ± SD。偏態的變數則使用 median 和 IQR
2.偏態分布判定指標:(mean/SD)<2
3.連續變數的直方圖和分類變數的次數分配表,以及遺漏資料的百分比,作為補充材料提供。
二、評估統計假設是否成立,尤其是線性關係
所有的統計分析都是建立在一些基本假設之上,統計模型的有效性取決於進一步的假設,這些假設需要進行評估。多數迴歸模型的重要假設為數據在一定範圍內呈線性關係,可以使用多項式或擬合曲線等方法對其進行評估。
三、應準確報告p值,並關注臨床重要性
p值可提供資料與統計假設或模型相容性的有用資訊,因此應準確報告,而不是用「是否顯著」的定性結論來代替。相容性可以通過基於拋硬幣實驗的p值轉換(稱為s值)來衡量。不要將p值直接二分法顯示為0.05或0.01。尤其是,不應將較大的p值解釋為沒有關聯或沒有影響:沒有證據並不代表不存在。只有無效值(差異為 0,比率為 1)附近的區間估計值非常小,才有理由推論該研究沒有發現重要的關聯或效果。換句話說,應根據適當指標的區間估計值(如均值差或風險差)來判斷結果的臨床重要性。
四、辨識干擾因子
在因果關係探討上,干擾因子的辨識與調整至關重要。應根據背景因果資訊選擇干擾因素--例如,有向無環圖(directed acyclic graphs,DAGs)所示。而非基於有無顯著性,如逐步選擇法,可能會遺漏重要的干擾因子,產生很大的誤導。
五、遺漏值的處理
遺漏值在數據上很常見,若遺漏比例較高(例如,>5 %),應避免使用簡單作法,如完整病例分析(即直接刪除遺漏個案,僅使用完整數據)、遺漏指標(missingness indicators)或末次觀察值結算法(last-observation-carried-forward),可能會產生很大的偏差。更好的方法包括逆概率加權(inverse probability weighting)、多重插補法(multiple imputation)。
六、稀疏資料(sparse data)的分析建議
稀疏資料(sparse data)是Logistic迴歸或Cox迴歸一個重要的偏差來源。稀疏資料(sparse data)亦即某些變數組別中的事件數較少。OR不合理地大和信賴區間較寬(如OR=10,95% CI = 2-50)常提示存在資料稀疏偏差,可以通過懲罰函數或貝葉斯法減少偏差。調整後的相對危險性RR(risk ratio)在評估臨床相關性方面優於OR(odds ratio),因前者更容易合理解釋,並對稀疏資料具有較佳的抗力。在世代研究和隨機對照試驗中可使用改良的Poisson 迴歸 或標準化迴歸係數來估計相對危險性(RR)和風險差(RD)
七、交互作用
許多研究試圖探討兩種治療方法的交互作用對結局的影響,或是想要估計一種治療方法被另一種方法調整的程度(即effect-measure modification)。研究者常在迴歸模型,如logistic或Cox迴歸中加入乘積項(product terms)代表累乘交互作用(multiplicative interactions),但在臨床決策和公共健康角度來看,累加交互作用(additive interaction)更為重要,也應該進行評估。此外,研究者在確立交互作用的方向上通常能力不足,若僅透過統計檢定篩檢交互作用可能產生誤導性估計。
#臨床研究 #統計學 #如何報告統計結果 #臨床意義 #統計意義 #報告指引 #spss #匯東華 #統計課程 #零基礎醫學統計
![]()
數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。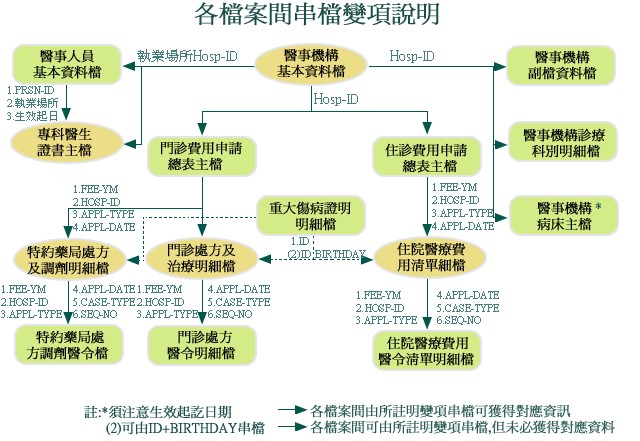
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
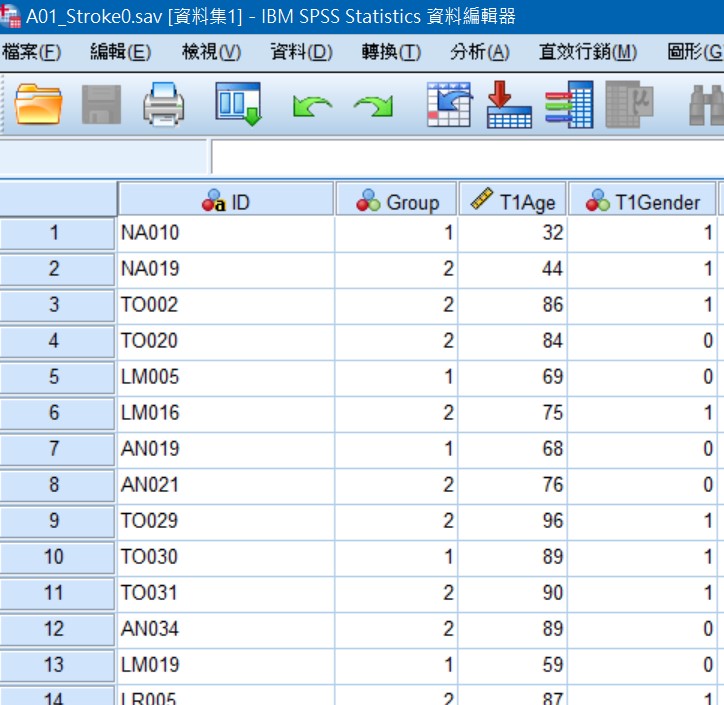
Fig2.整併與清理為可分析的table
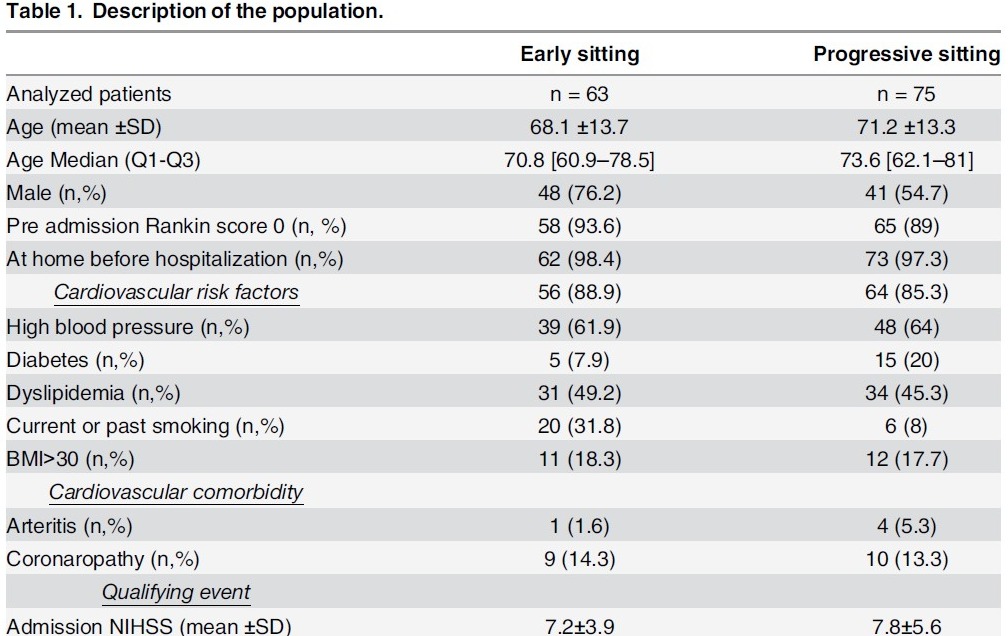
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖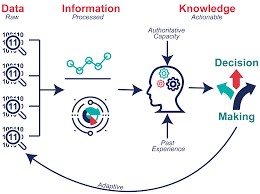
![]()
教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk
![]()
計畫撰寫與統計諮詢


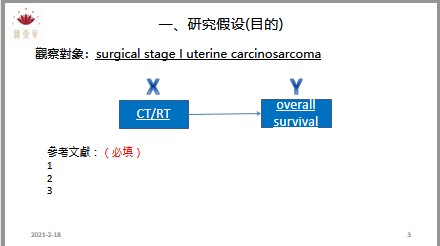
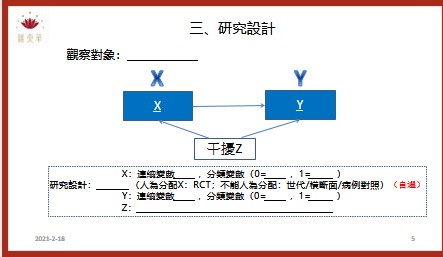
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。